Shadowsocks/Vmess到底怎么选?安全性如何?
Shadowsocks/Vmess到底怎么选?安全性如何?
起因
入冬后,准确来说是在秋季,就感觉原来的小机场偶尔会出现大批节点无法连接的情况,今年1月底到期,在考虑几年了是否该更换跑路,不过好在相对便宜,故障一会就好,还能接受。
然而在将要到期的前几天的时间点上,它刚好又出现了中断,且持续了近1个小时,这对打工人来说不太能接受了,于是便舍弃了原来的小机场,投奔朋友推荐的更大一家。
但这里有两个问题,一个是用什么代理软件,第二个是用什么代理协议,这两个问题是逐步浮现的。
代理软件
由于个人职业与所处行业原因,接触墙外比较早(小时候到外服体验新版本游戏),也在之前就尝试自己搭过VPS,详见Try-for-V2Ray,后来由于Vultr质量真的不堪入目、WS+TLS需要的域名证书也是一笔费用且麻烦(才不是懒),项目算是咕掉了,但其中学习到的知识与相关技术还没全忘,用到的各种代理软件也还是多的。
Clash
你要我从中选择,移动端PC端我都会毫不犹豫的选择Clash,谁能拒绝可爱猫猫?但是,可爱猫猫在2023年11月寄掉了!与之相关的Core、Pro、X等都闻风而逝(只猫,影逝二度),仅留下永远停止更新的本地客户端。
虽然现在才1月底,最后一次release在3个月前,但时间越长,对于一个曾开源项目来说就越危险,必须要有可行的安全性选择(我也曾考虑过不这么麻烦,直接用之前的不就好了,然后我在互联网上“看着不错还蛮正经”的网站上获取的ClashX远程服务端口就被修改过了)。

V2rayU
撰写此文时,我新入职的公司使用的是MAC M2办公,在第一家公司就使用MAC的我并无什么不适应,但是ClashX在我入职前就化作灰烬,我在换机场前就已经在使用V2rayU,这是个专走Vmess协议的Proxy,虽然repo已有两年未更新了,但是release其实作者一直在偷偷更新。
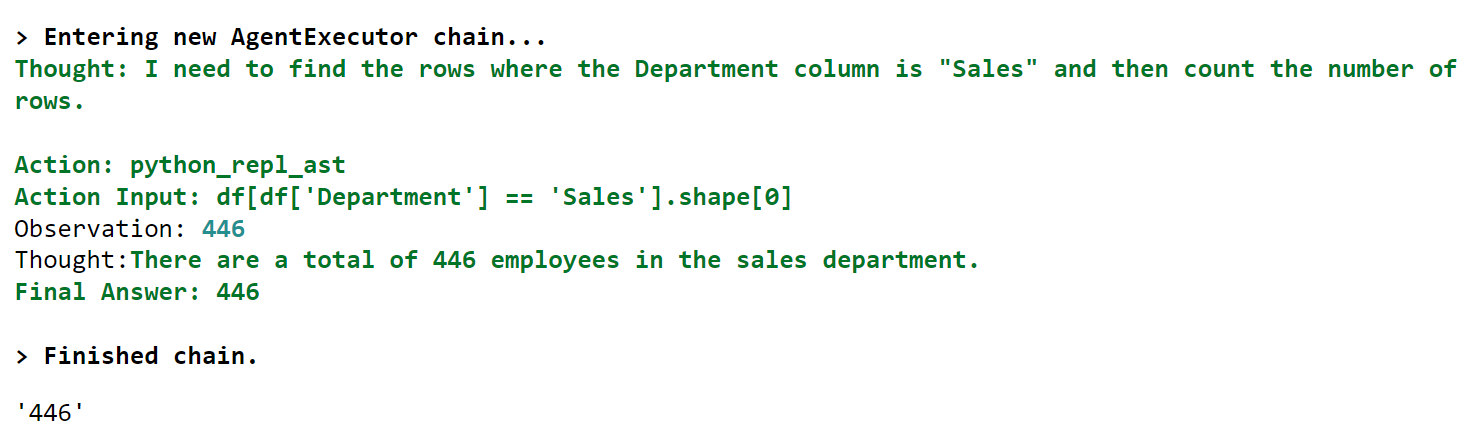
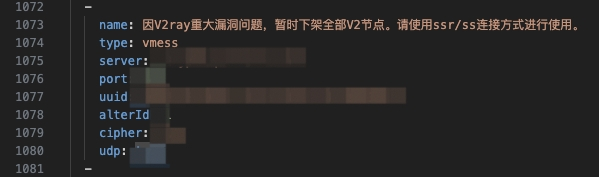
然而,当我切换到新的机场订阅时,却发现机场节点的一句提醒:
因V2ray重大漏洞问题,暂时下架全部V2节点。请使用ssr/ss连接方式进行使用

代理协议
所以这是怎么回事?
我依稀记得我玩个人VPS那些年还在传VMESS协议更加安全,V2ray可以用更多的传输配置才对啊?这个重大漏洞是什么,CVE编号多少?(啊,这就是职业病)
V2ray重大漏洞
漏洞的描述简单来说就是:
v2ray的TLS流量可被简单特征码匹配精准识别,vmess协议设计和实现缺陷可导致服务器遭到主动探测特征识别
这两方面的问题不论哪个都会使得用V2ray作为Proxy、VMESS作协议进行传输的墙外访问方式被轻松识别到,虽然不同于传统安全漏洞,但确实是严重问题。
服务器端的 V2ray 更新到 v4.23.4 以及之后的版本可以解决这一问题, 请大家尽快更新.
截止本文撰写,V2ray-Core的最新release已经到5.12.1,可是这个问题应该早已经被修复了,为什么现在订阅还有这样的提示,不让使用VMESS协议?

如何选择
绕一大圈,让我们回到文章的主标题:
Shadowsocks/Vmess到底怎么选?安全性如何?
先说结论:它们最新版本的实现都是安全的,也都是不安全的
为什么这么说?
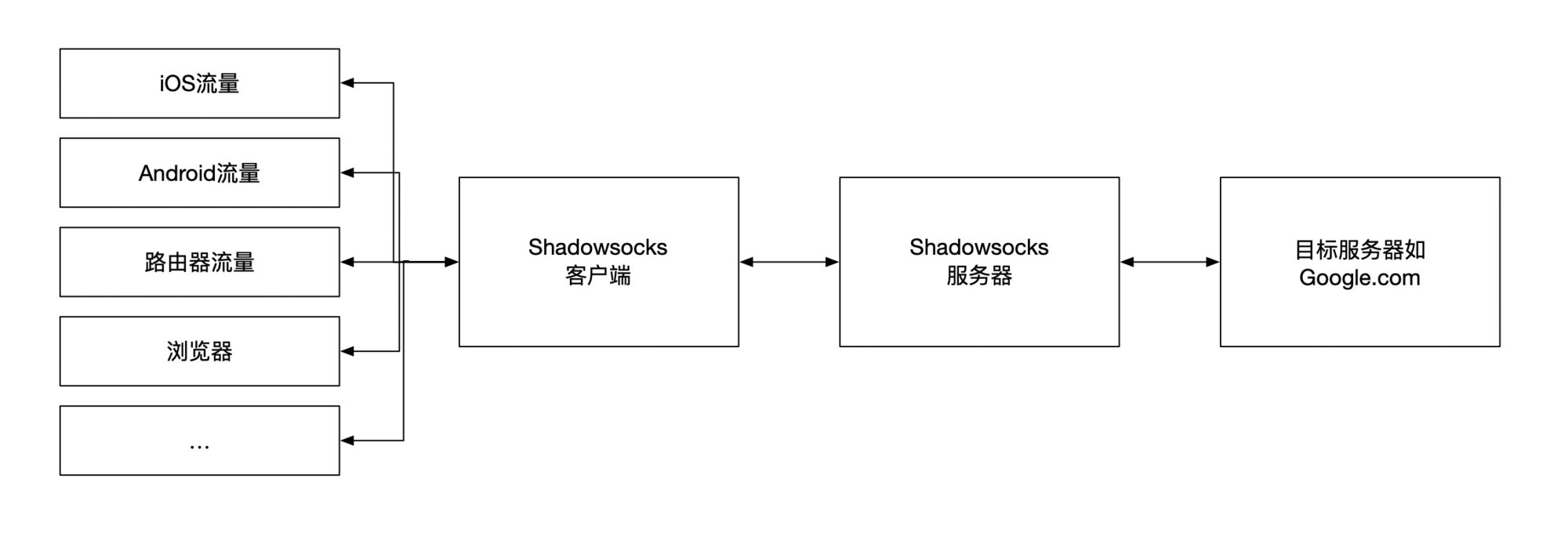
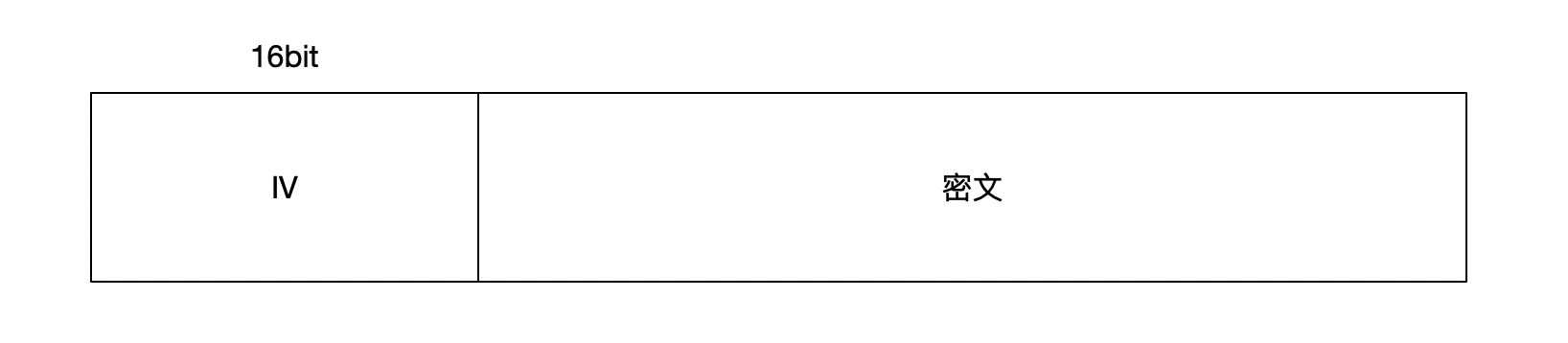
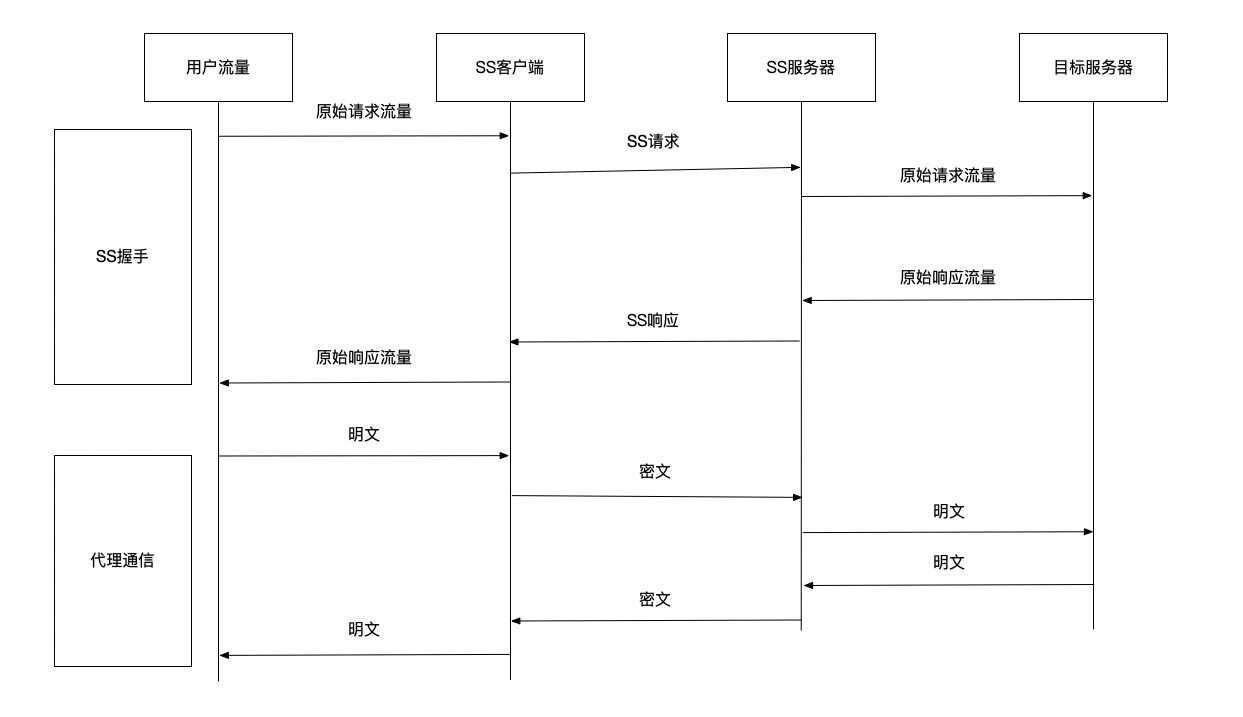
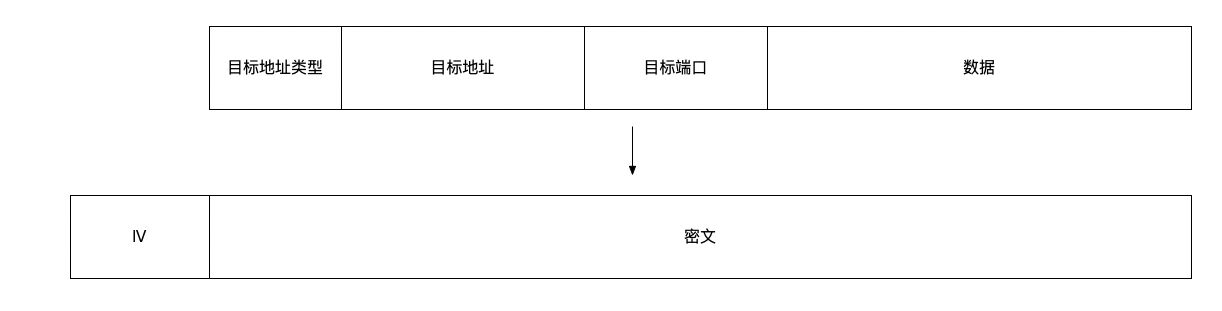
对于这两种协议甚至更多种的传输协议,想要去了解它的具体实现及传输形式并不难,以Shadowsocks为例,在Shadowsocks协议解析一文中有清晰明了的叙述,Vmess你也应该都能找到类似的内容。
Shadowsocks/Vmess都会采用一定的加密算法,将传输内容进行加密,在浅谈一下Shadowsocks和VMess的安全性一文的评论中,enfein有提到“shadowsocks 协议现阶段还是安全的,但 VMess 在一些领域做得更好,例如使用依赖于时间的密钥生成办法”,这也佐证了我最初认为Vmess协议的安全性设计比Shadowsocks好的看法,那就能说明Vmess安全性更好吗?


主要漏洞
我们回忆一下前文提到的“V2ray重大漏洞”,虽然没有被直接破解出传输内容明文,但能精确地探测标识proxy服务器,与在黑暗森林中点火且大喊无异。
那么Shadowsocks有这样的问题吗?
在浅谈一下Shadowsocks和VMess的安全性的原文中,作者例举了两个Shadowsocks的相关漏洞:
Shadowsocks AEAD 加密方式设计存在严重漏洞,无法保证通信内容的可靠性
shadowsocks redirect attack exploit
前者也会使proxy服务器因为流量特征被标识而封禁,后者则更致命地可导致传输内容密文被解析。

最佳实践
既然大家都是卧龙凤雏,有什么不那么烂的方式吗?
首先要明确的是,最新版本的协议都已经将已知漏洞修复,可以认为两者安全性相近,也都有可能被流量分析与主动探测(即使你采取了防范与伪装)。
针对Shadowsocks,防御GFW主动探测的实用指南一文中指出了Shadowsocks理应达到的最佳实践;相应的,Vmess支持和TLS组合,也可以实现动态端口等,这些在我搭建VPS的时候就已经是个人可以不算复杂的实现了。并且在【还Shadowsocks一个清白】Shadowsocks是如何被检测和封锁的,兼谈ss配置策略一文中,也有提到可以采用国内转国外双重代理的方式,规划ip白名单,规避一些探测(但文章内容主观性较强,观点接纳需分别):
此外,在搭建与使用的过程中,不能过分信任某些教程,并不是说它们的方法有问题,而是很多一键部署的脚本为了运行的稳定性与一致性,是写死了引用版本的,那么就很有可能还在利用存在漏洞的协议版本;同时也需要注意客户端的选择,个人现在使用的是Clash Verge Rev(回来吧我的牢猫!),Clash Verge的原repo也因为2023年11月的风波停止更新,Rev是抛弃了原Clash Core(repo removed)采用mihomo重新构建并仍在更新的版本。
那为什么不使用V2ray相关的客户端?
一方面是新的机场不支持Vmess(前情提要),一方面是V2ray Core做出的客户端确实没有猫猫可爱(猫猫也支持Vmess等多种协议),再一方面是有些V2ray的客户端的最新release用的Core版本仍处于风险版本(V2rayU:所以爱是会消失的对吗?)


机场顾虑
最后一个问题,既然Shadowsocks和Vmess都可以,为什么有些机场不提供Vmess节点了?
这个问题在关于科学上网的流行说法一文中可见一斑:
- 大部分机场都是中转线路,使用 V2RAY 显得太重,消耗服务器资源大
- V2RAY在防标识的场景下相比已经搭好的Shadowsocks没有明显优势
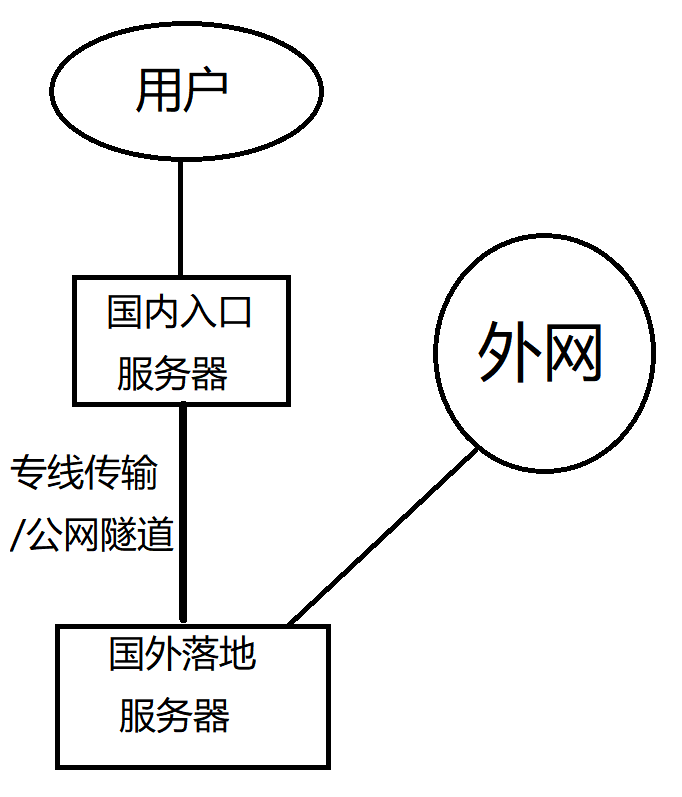
所以对于机场线路,公网隧道、专线,没有一定要再采用哪种协议的需求,更多地在考虑带宽等费用与访问流畅度。此外,机场躲避封锁的方式,在文章中也有谈及,同时文章中也有谈到订阅转换的技术,在一些机场也有提供(在逐渐收敛)。
个人小注
对于浏览访问来说,机场提供的服务已经完全够用,除了不能登录服务器进行配置这部分不便,这也是我为什么暂时放弃了自己搭建VPS的想法;
但对于未来的渗透测试来说,虽然简单的OOB可以Dnslog/Ceye,但如果要弹shell,或者境外测试,就还是需要国内云与国外云的服务,这些机场就完全无法支持了。

参考引用
Shadowsocks AEAD 加密方式设计存在严重漏洞,无法保证通信内容的可靠性
shadowsocks redirect attack exploit