使用 ChatGPT 与 Python 中的第三方应用程序进行交互
使用 ChatGPT 与 Python 中的第三方应用程序进行交互
本文转自Miloce 并作补充
将语言模型(如ChatGPT)集成到第三方应用程序中已经变得越来越流行,因为它们能够理解和生成类似人类的文本。然而,需要认识到ChatGPT的一些限制,比如它的知识截止日期是在2021年9月,以及它无法直接访问维基百科或 Python 等外部资源。
鉴于这一挑战,LangChain的联合创始人兼首席执行官Harrison Chase提出了一个创新的解决方案。他开发了Python LangChain模块,该模块使开发人员能够轻松地将第三方应用程序与大型语言模型集成在一起。这一突破开启了无限的可能性,允许开发人员充分利用语言模型的强大功能,同时有效地处理来自外部来源的信息。
在本文中,我们将探讨使用Python LangChain模块与ChatGPT交互以与第三方应用程序交互的有趣概念。到文章末尾,您将更深入地了解如何利用这种集成,创建更复杂和高效的应用程序。
导入ChatGPT模块
第一步是安装Python LangChain模块,您可以使用以下pip命令完成此操作。
接下来,您需要从
langchain.chat_models模块导入ChatOpenAI类。ChatOpenAI类允许您创建ChatGPT的实例。为此,请将model_name属性传递给ChatOpenAI类,将模型设置为”gpt-3.5-turbo”。OpenAI的”gpt-3.5-turbo”模型为ChatGPT提供动力。您还需要将您的OpenAI API密钥传递给open_api_key属性。
2
3
4
5
6
import os
api_key = os.getenv('OPENAI_KEY2')
chatgpt = ChatOpenAI(model_name="gpt-3.5-turbo",
openai_api_key=api_key)现在,我们已准备好在Python中将第三方应用程序与ChatGPT集成。
使用ChatGPT从维基百科提取信息
如前所述,ChatGPT的知识截止日期为2021年9月,无法回答那之后的查询。例如,如果您要求ChatGPT返回2022年温布尔登锦标赛的维基百科文章摘要,您将获得以下答案:
LangChain代理允许您与第三方应用程序交互。有关更多信息,请查看所有LangChain代理集成的列表。
让我们看看如何使用示例代码将ChatGPT与维基百科等第三方应用程序集成。
您需要从
langchain.agents模块导入load_tools、initialize_agent和AgentType实体。接下来,您应该将代理类型作为输入提供给
load_tools类。在下面的示例脚本中,指定的代理类型是wikipedia。随后的步骤涉及使用initialize_agent()方法创建代理对象。在调用initialize_agent()方法时,您需要传递工具类型、ChatGPT实例和代理类型作为参数。如果将verbose参数设置为True,它将显示代理任务执行的思考过程。在下面的脚本中,我们要求维基百科代理返回2022年温布尔登锦标赛的维基百科文章摘要。
在输出中,您可以看到代理的思考过程以及包含文章摘要的最终结果。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
tools = load_tools(
['wikipedia'],
)
agent_chain = initialize_agent(
tools,
chatgpt,
agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
verbose=True,
)
agent_chain.run(
"返回2022年温布尔登锦标赛的维基百科文章摘要。"
)


从ArXiv提取信息
让我们看看另一个示例。我们将从ArXiv获取一篇文章的标题和作者姓名,ArXiv是一个流行的开放获取科研论文、预印本和其他学术文章的存储库。
脚本保持不变,只需将
arxiv作为参数值传递给load_tools()方法。
2
3
4
5
6
7
8
9
10
11
12
13
14
["arxiv"],
)
agent_chain = initialize_agent(
tools,
chatgpt,
agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
verbose=True,
)
agent_chain.run(
"给我提供文章1301.3781的标题和作者姓名。"
)

从CSV文件提取信息
LangChain提供了直接创建特定任务代理实例的方法。例如,
langchain.agents模块的create_csv_agent()方法允许您创建与CSV文件交互的CSV代理。让我们看一个示例。以下脚本导入包含公司员工流失信息的数据集。
2
3
4
5
dataset = pd
.read_csv(r'D:\Datasets\employee_attrition_dataset.csv')
dataset.head()
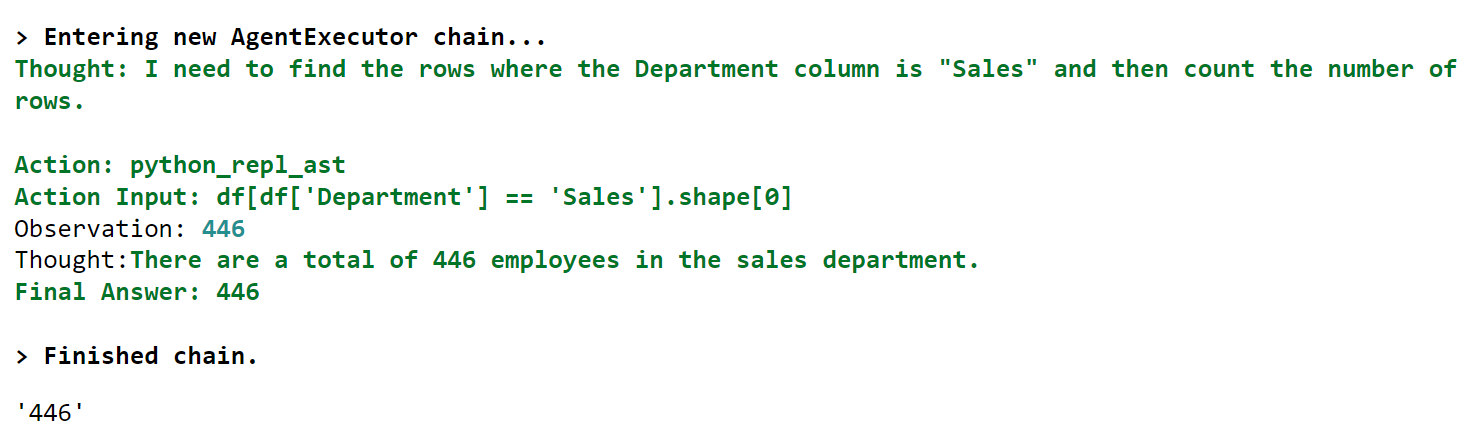
让我们使用CSV代理从此文件获取信息。我们要求ChatGPT返回销售部门的员工总数。
在输出中,您可以看到ChatGPT返回输出的过程。
2
3
4
5
6
7
8
9
agent = create_csv_agent(
chatgpt,
r'D:\Datasets\employee_attrition_dataset.csv',
verbose=True
)
agent.run("返回销售部门的员工总数。")
从Pandas DataFrame提取信息
同样,您可以使用
create_pandas_dataframe_agent()方法从Pandas dataframe中提取信息。在下面的脚本中,我们要求ChatGPT返回销售部门中教育领域为医学的员工总数。
2
3
4
5
6
7
8
9
10
11
12
dataset = pd.read_csv(r'D:\Datasets\employee_attrition_dataset.csv')
from langchain.agents import create_pandas_dataframe_agent
agent = create_pandas_dataframe_agent(
chatgpt,
dataset,
verbose=True
)
agent.run("返回销售部门中教育领域为医学的员工总数。")
至此,教程结束。希望您会喜欢它!
