【组件攻击链】XStream组件高危漏洞分析与利用
本文转自 深信服千里目安全技术中心 并作补充
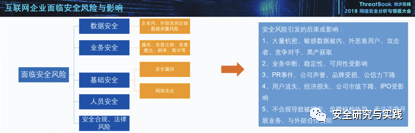
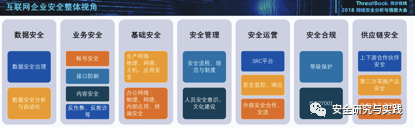
组件介绍
XStream是Java类库,用来将对象序列化成XML(JSON)或反序列化为对象。XStream在运行时使用Java反射机制对要进行序列化的对象树的结构进行探索,并不需要对对象作出修改。XStream可以序列化内部字段,包括私private和final字段,并且支持非公开类以及内部类。在缺省情况下,XStream不需要配置映射关系,对象和字段将映射为同名XML元素。但是当对象和字段名与XML中的元素名不同时,XStream支持指定别名。XStream支持以方法调用的方式,或是Java标注的方式指定别名。XStream在进行数据类型转换时,使用系统缺省的类型转换器。同时,也支持用户自定义的类型转换器。XStream类图:
高危漏洞介绍
XStream组件漏洞主要是java反序列化造成的远程代码执行漏洞,目前官方通过黑名单的方式对java反序列化攻击进行防御,由于黑名单防御机制存在被绕过的风险,因此以后可能会再次出现类似上述java反序列化漏洞。
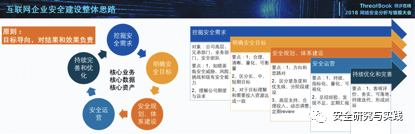
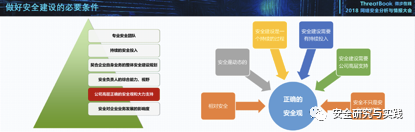
漏洞利用链 1 组件风险梳理
根据XStream组件的漏洞,结合XStream常用的使用场景,得到如下风险梳理的场景图。
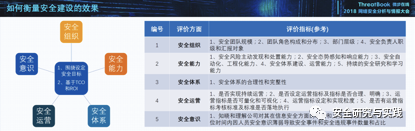
2 利用链总结
基于风险梳理思维导图,总结出一种漏洞的利用场景。
无权限 -> GetShell
高可利用漏洞分析
从高危漏洞列表中,针对部分近年高可利用漏洞进行漏洞深入分析。
技术背景 java动态代理
Java标准库提供了一种 动态代理(Dynamic Proxy) 的机制:可以在运行期动态创建某个interface的实例。
例子: 我们先定义了接口Hello,但是我们并不去编写实现类,而是直接通过JDK提供的一个Proxy.newProxyInstance()创建了一个Hello接口对象。这种没有实现类但是在运行期动态创建了一个接口对象的方式,我们称为动态代码。JDK提供的动态创建接口对象的方式,就叫动态代理。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 package test3_proxyclass;import java.lang.reflect.InvocationHandler;import java.lang.reflect.Method;import java.lang.reflect.Proxy;public class Main { public static void main (String[] args) { InvocationHandler handler = new InvocationHandler () { @Override public Object invoke (Object proxy, Method method, Object[] args) throws Throwable { System.out.println(method); if (method.getName().equals("morning" )) { System.out.println("Good morning, " + args[0 ]); } return null ; } }; Hello hello = (Hello) Proxy.newProxyInstance( Hello.class.getClassLoader(), new Class [] { Hello.class }, handler); hello.morning("Bob" ); } } interface Hello { void morning (String name) ; }
java动态代理机制中有两个重要的类和接口InvocationHandler(接口)和Proxy(类),这一个类Proxy和接口InvocationHandler是我们实现动态代理的核心;
**InvocationHandler接口:**proxy代理实例的调用处理程序实现的一个接口,每一个proxy代理实例都有一个关联的调用处理程序;在代理实例调用方法时,方法调用被编码分派到调用处理程序的invoke方法。
**newProxyInstance:**创建一个代理类对象,它接收三个参数,我们来看下几个参数的含义:
1 2 3 4 5 loader:一个classloader对象,定义了由哪个classloader对象对生成的代理类进行加载 interfaces:一个interface对象数组,表示我们将要给我们的代理对象提供一组什么样的接口,如果我们提供了这样一个接口对象数组,那么也就是声明了代理类实现了这些接口,代理类就可以调用接口中声明的所有方法。 h:一个InvocationHandler对象,表示的是当动态代理对象调用方法的时候会关联到哪一个InvocationHandler对象上,并最终由其调用。
getInvocationHandler : 返回指定代理实例的调用处理程序
getProxyClass : 给定类加载器和接口数组的代理类的java.lang.Class对象。
isProxyClass : 当且仅当使用getProxyClass方法或newProxyInstance方法将指定的类动态生成为代理类时,才返回true。
newProxyInstance : 返回指定接口的代理类的实例,该接口将方法调用分派给指定的调用处理程序。
1 XStream 远程代码执行漏洞 1.1 漏洞信息
1.1.1 漏洞简介
● 漏洞名称:XStream Remote Code Execution Vulnerability
● 漏洞编号:CVE-2013-7285
● 漏洞类型:Remote Code Execution
● CVSS评分:CVSS v2.0:7.5 , CVSS v3.0:9.8
● 漏洞危害等级:高危
1.1.2 漏洞概述
包含类型信息的流在unmarshalling时,会再次创建之前写入的对象。因此XStream会基于这些类型信息创建新的实例。攻击者可以操控XML数据,将恶意命令注入在在可以执行任意shell命令的对象中,实现漏洞的利用。
1.1.3 漏洞利用条件
无
1.1.4 漏洞影响
影响版本:XStream <= 1.4.6
1.1.5 漏洞修复
获取XStream最新版本,下载链接:https://x-stream.github.io/download.html
1.2 漏洞复现
1.2.1 环境拓扑
1.2.2 应用协议
8080/HTTP
1.2.3 环境搭建
基于Windows平台,使用环境目录下的xstreamdemo环境,拷贝后使用Idea打开xstreamdemo文件夹,下载maven资源,运行DemoApplication类,即可启动环境。效果如图。
1.2.4 漏洞复现
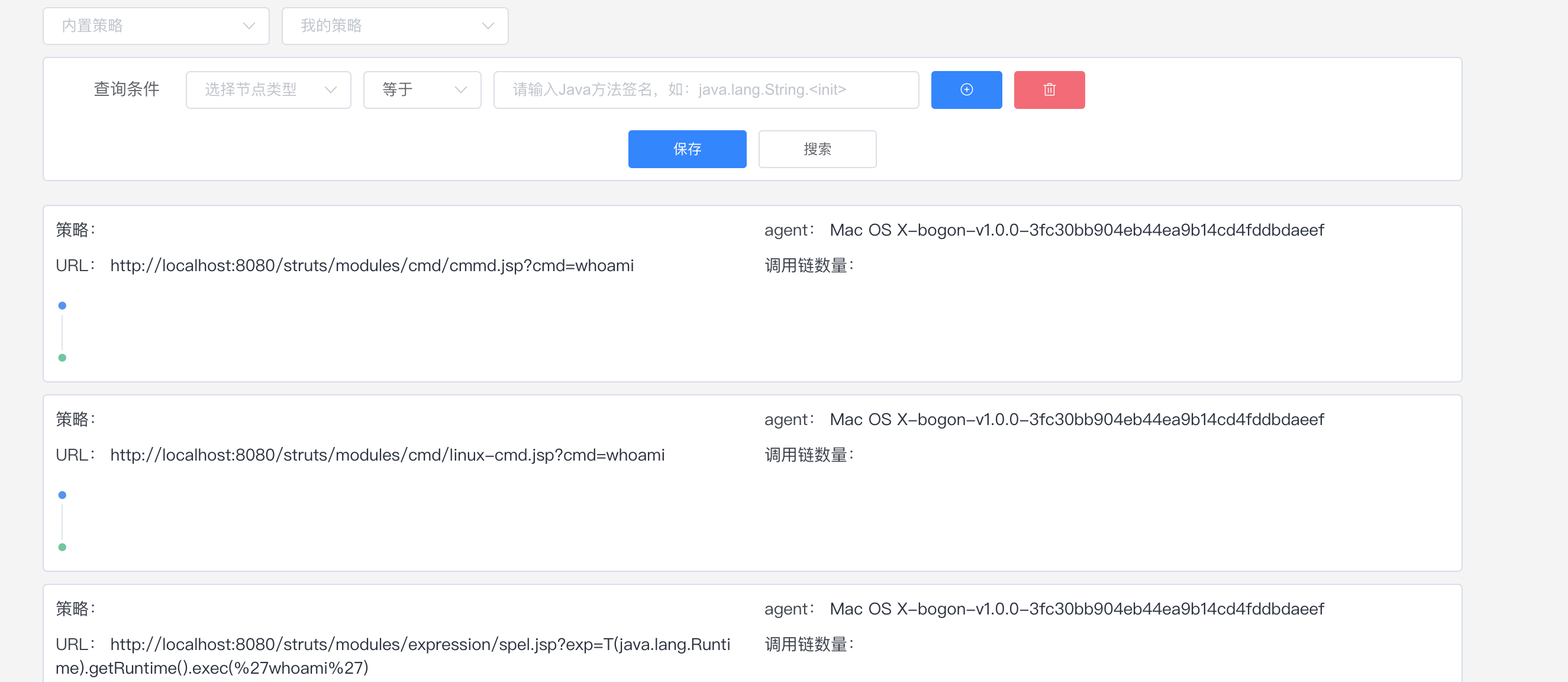
运行sniper工具箱,填写表单信息,点击Attack,效果如图。
1.3 漏洞分析
1.3.1 代码分析
传入的payload首先会在com.thoughtworks.xstream.XStream的fromXML()方法中处理,在进入unmarshal()方法中进行解集。
在com.thoughtworks.xstream.core.AbstractTreeMarshallingStrategy类中的unmarshal()方法中调用start()方法进行Java对象转换。
在com.thoughtworks.xstream.core.TreeUnmarshaller类中的start()方法通过调用readClassType()获取type类型。
在readClassType()方法中调用readClassAttribute方法。
进入readClassAttribute方法调用aliasForSystemAttribute方法获取别名。调用getAttribute方法,获取reader对象中记录的外部传入XML数据中是否存在对应的标签,如果不存在则返回null。
回到HierarchicalStreams#readClassType方法中调用realClass方法,通过别名在wrapped对象中的Mapper中循环查找,获取与别名对应的类。
找到sorted-set别名对应的java.util.SortedSet类,并将类存入realClassCache对象中。
回到TreeUnmarshaller#start方法,调用convertAnother方法。进入convertAnother方法后,调用defaultImplementationOf方法,在mapper对象中寻找java.util.SortedSet接口类的实现类java.util.TreeSet。
获取java.util.TreeSet类型,调用lookupConverterForType方法,寻找对应类型的转换器。进入lookupConverterForType方法,循环获取转换器列表中的转换器,调用转换器类中的canConvert方法判断选出的转换器是否可以对传入的type类型进行转换。
转换器TreeSetConverter父类CollectionConverter中canConvert方法判断,传入的type与java.util.TreeMap相同,返回true,表示可以使用TreeSetConverter转换器进行转换。
回到DefaultConverterLookup#lookupConverterForType方法,将选取的converter与对应的type存入typeToConverterMap。
回到TreeUnmarshaller#convertAnother方法中,调用this.convert方法。
首先判断传入的xml数据中是否存在reference标签,如果不存在,则将当前标签压入parentStack栈中,并调用父类的convert方法。
进入convert方法中,调用转换器中的unmarshal方法,对传入的xml数据继续解组。
首先调用unmarshalComparator方法判断是否存在comparator,如果不存在,则返回NullComparator对象。
根据unmarshalledComparator对象状态,为possibleResult对象赋予TreeSet类型对象。
由于possibleResult是一个空的TreeMap,因此最终treeMap也是一个空对象,从而调用treeMapConverter.populateTreeMap方法。
进入populateTreeMap方法中,首先调用调用putCurrentEntryIntoMap方法解析第一个标签,再调用populateMap方法处理之后的标签(此流程中二级标签只存在一个,因此在处理二级标签时暂不进入populateMap方法)。
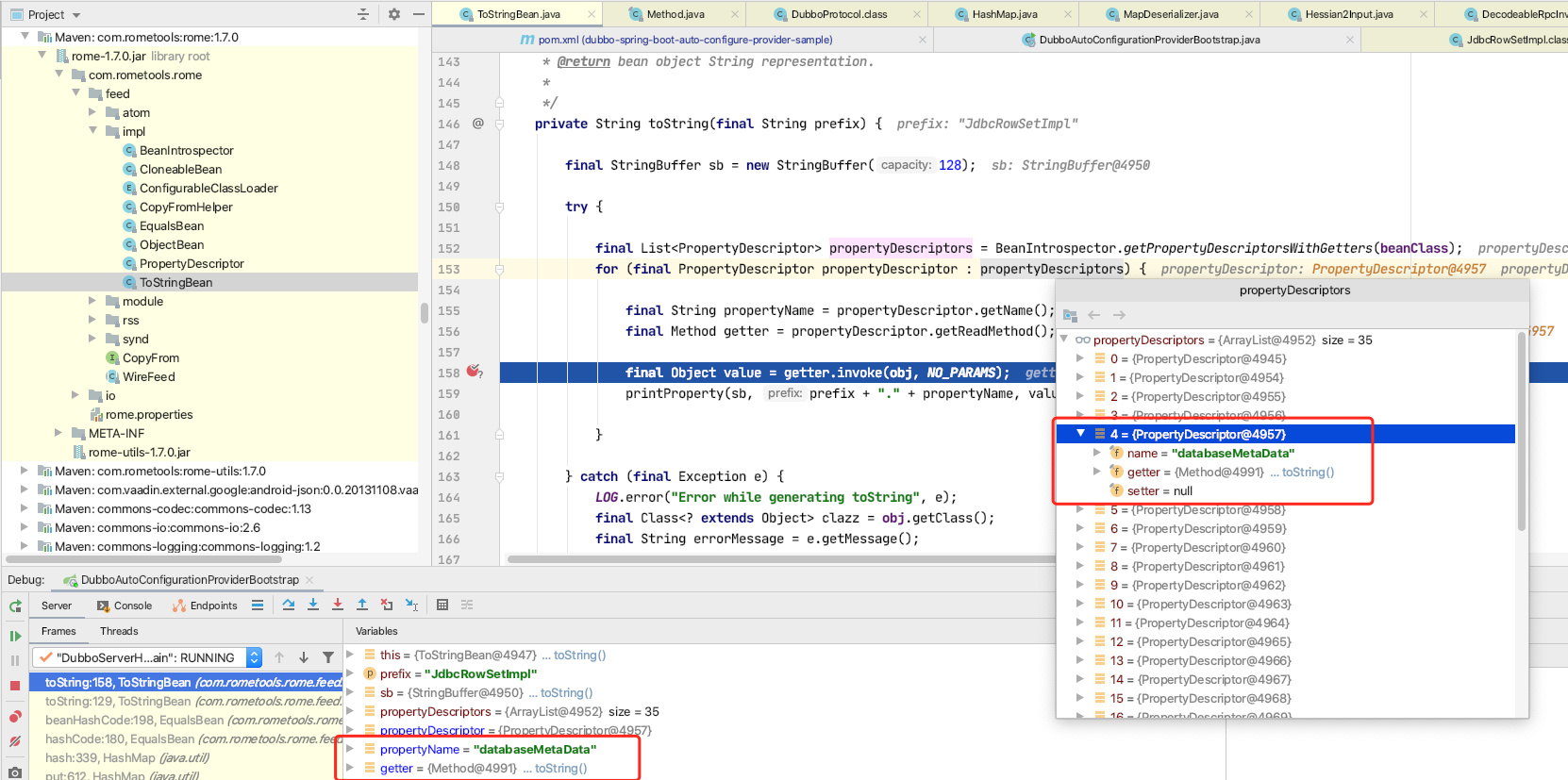
具体调用流程如下,com.thoughtworks.xstream.converters.collections.TreeSetConverter类中调用putCurrentEntryIntoMap方法 -> com.thoughtworks.xstream.converters.collections.AbstractCollectionConverter.readItem() 中的 readClassType()方法获取传入xml数据中标签名(别名)对应的类(与本节中获取sorted-set对应类的流程相同)。本次获取的是dynamic-proxy对应的java.lang.reflect.Proxy.DynamicProxyMapper类型,并将别名与类型作为键值对,存入realClassCache中。
回到AbstractCollectionConverter.readItem()方法中,调用convertAnother方法,寻找DynamicProxyMapper对应的convert,获取到DynamicProxyConverter转换器。
得到com.thoughtworks.xstream.mapper.DynamicProxyMapper$DynamicProxy,按照之前获取转换器之后的流程,调用转换器中的unmarshal()方法获取interface元素,得到java.lang.Comparable,并添加到mapper中。
在通过循环查询,继续查找下面的节点元素,进而获得了handler java.beans.EventHandler。
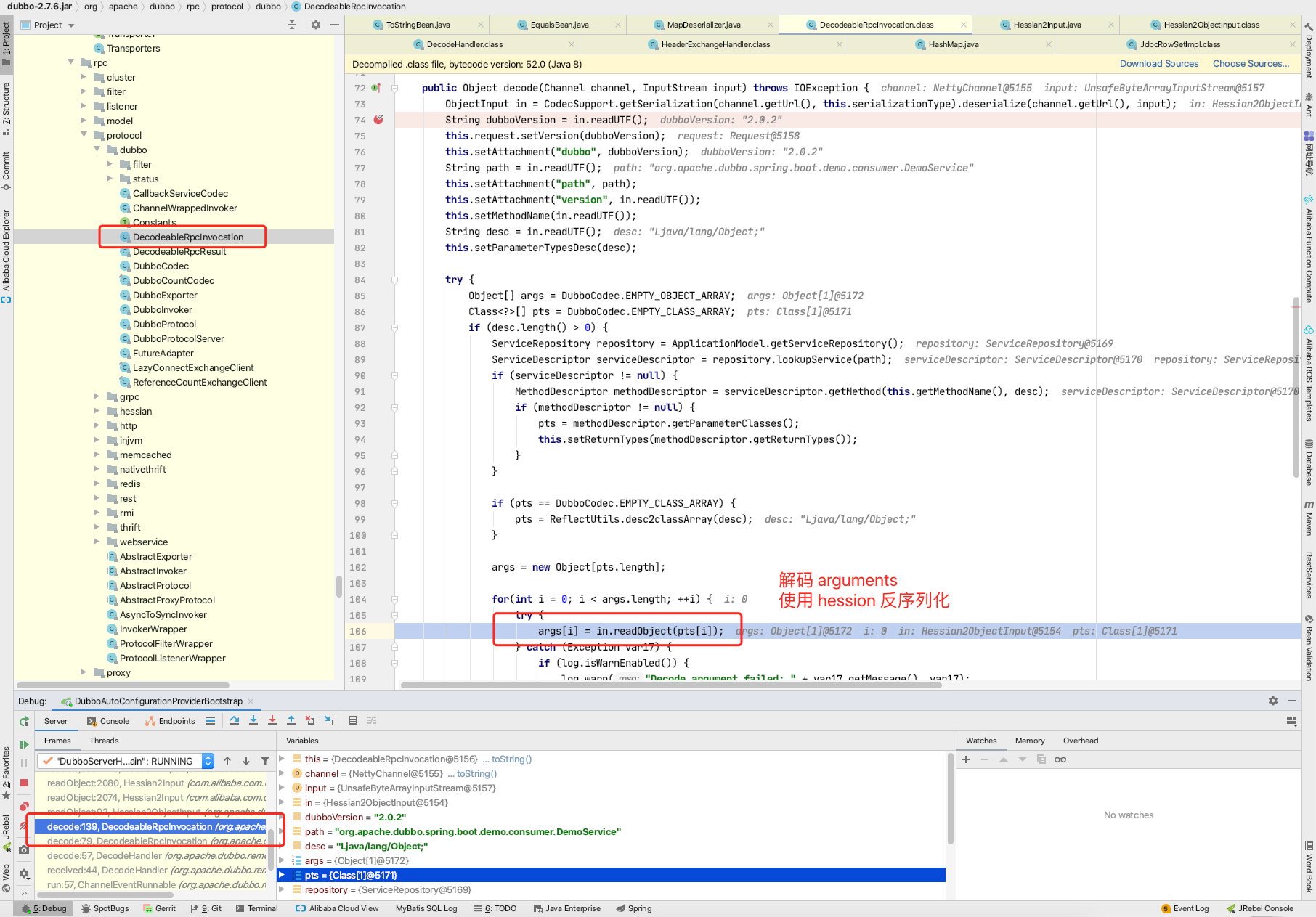
调用Proxy.newProxyInstance方法创建动态代理,实现java.lang.Comparable接口。
调用convertAnother方法获取传入type的转换器,java.beans.EventHandler对应的convert是ReflectionConverter。并将父类及其对象写进HashMap中
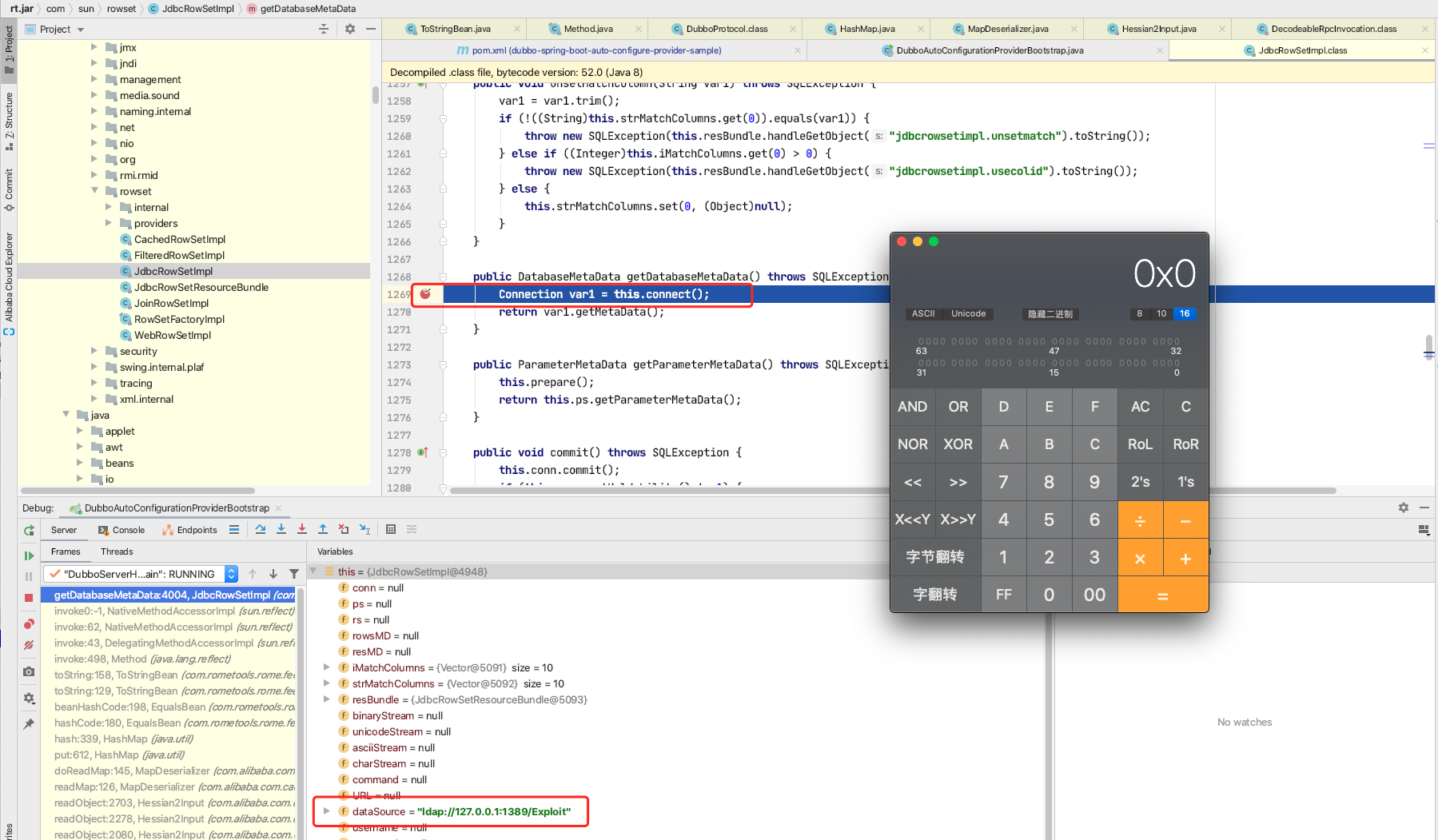
在com.thoughtworks.xstream.converters.reflection.AbstractReflectionConverter.duUnmarshal()方法获取下面的节点元素target java.lang.ProcessBuilder。
具体流程如下:调用getFieldOrNull方法,判断xml格式中传入的标签名在目标类中是否存在对应属性。
在调用reader.getNodeName()方法获取标签名,并赋值给originalNodeName。
调用realMember方法获取反序列化属性的名称。
调用readClassAttribute方法获取target标签中传入的类名
调用realClass获取上述过程中类名对应的类,并调用unmarshallField方法进行解析。
进入方法中,寻找对应type的转换器,由于是java.beans.EventHandler作为动态代理的实现类,所以选择的转化器都是ReflectionConverter 。使用选中的转换器进行解组。
使用ReflectionConverter convert处理java.lang.ProcessBuilder ,在duUnmarshal()方法获取command标签和comand标签下的String标签及其参数。(其中String标签下的参数是在下一层convert调用中获取的。)
调用this.reflectionProvider.writeField方法,将参数值传入对象中。
在按照获取target标签相同的流程获取action标签,最终将start方法存入对象中。
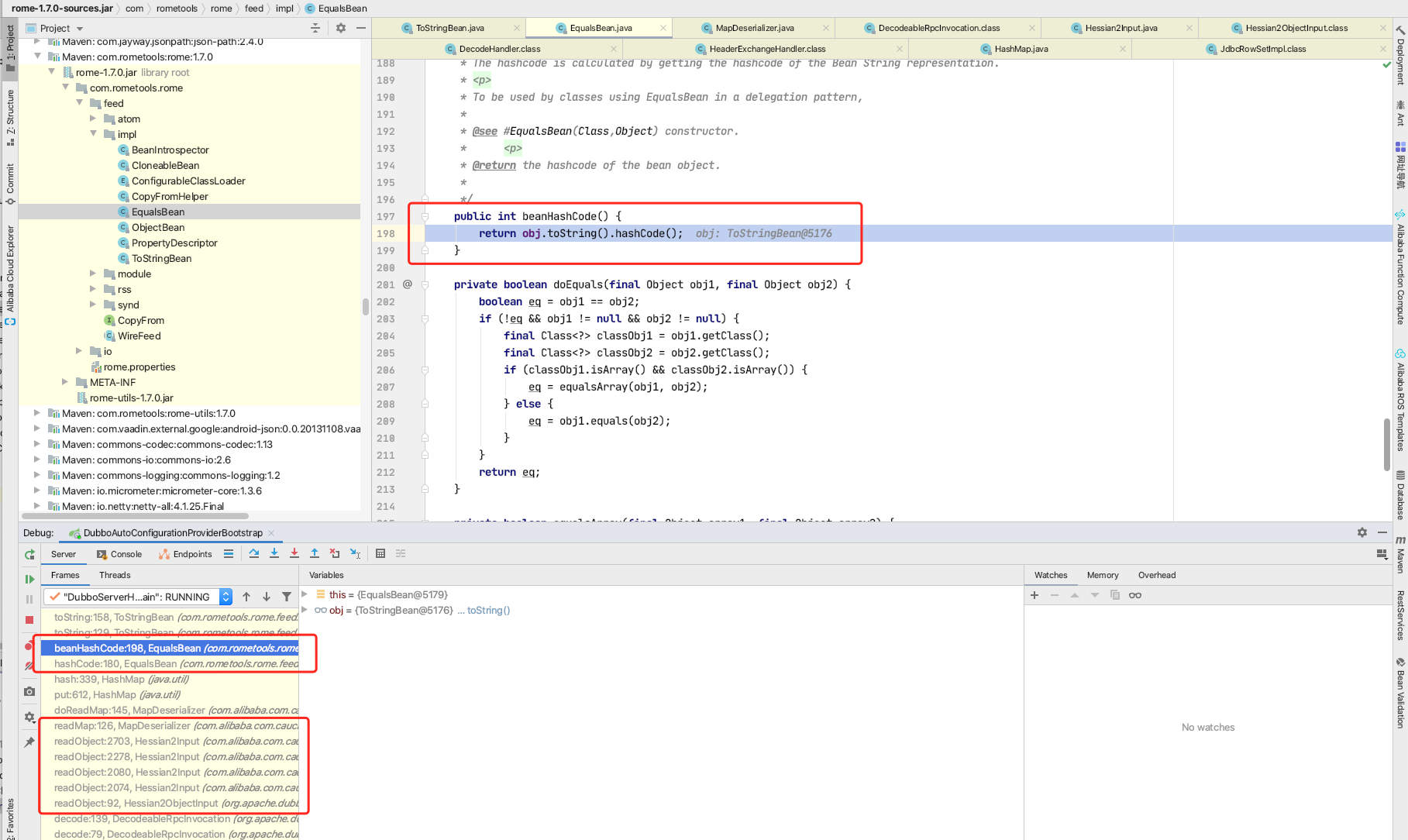
回到TreeMapConverter#populateTreeMap方法中,上述过程中构造的object保存在sortedMap中。且其中的动态代理实现的接口是java.lang.Comparable,因此只要调用java.lang.Comparable接口中的compareTo方法,即可触发动态代理,进入java.beans.EventHandler实现类中的invoke方法。在populateTreeMap方法中调用putAll方法,将sortedMap中的对象写入result变量的过程中会调用到compareTo,调用链如下。
进入java.beans.EventHandler#invoke方法中,通过反射执行对象中的方法。
1.3.2 补丁分析
XStream1.4.7版本中,在com.thoughtworks.xstream.converters.reflection.ReflectionConverter添加type != eventHandlerType阻止ReflectionConverter解析java.beans.EventHandler类。从而防御了此漏洞。
2 XStream 远程代码执行漏洞 2.1 漏洞信息
2.1.1 漏洞简介
● 漏洞名称:XStream Remote Code Execution Vulnerability
● 漏洞编号:CVE-2019-10173
● 漏洞类型:Remote Code Execution
● CVSS评分:CVSS v2.0:7.3 , CVSS v3.0:9.8
● 漏洞危害等级:高危
2.1.2 漏洞概述
包含类型信息的流在unmarshalling时,会再次创建之前写入的对象。因此XStream会基于这些类型信息创建新的实例。攻击者可以操控XML数据,将恶意命令注入在在可以执行任意shell命令的对象中,实现漏洞的利用。
2.1.3 漏洞利用条件
无
2.1.4 影响版本
影响版本:XStream = 1.4.10
2.1.5 漏洞修复
获取XStream最新版本,下载链接:https://x-stream.github.io/download.html
2.2 漏洞复现
2.2.1 拓扑图
2.2.2 应用协议
8080/HTTP
2.2.3 环境搭建
基于Windows平台,使用环境目录下的xstreamdemo环境,拷贝后使用Idea打开xstreamdemo文件夹,下载maven资源,运行DemoApplication类,即可启动环境。效果如图。
2.2.4 漏洞复现
运行sniper工具箱,填写表单信息,点击Attack,效果如图。
2.3 漏洞分析
2.3.1 代码分析
CVE-2019-10173漏洞与CVE-2013-7285漏洞原理相同,由于在XStream的安全模式默认不启动,导致防御失效。
Xstream 1.4.7对于漏洞的防御措施 :
通过在
com.thoughtworks.xstream.converters.reflection.ReflectionConverter添加type != eventHandlerType阻止ReflectionConverter解析java.beans.EventHandler类
Xstream 1.4.10漏洞产生原因 :
在com.thoughtworks.xstream.converters.reflection.ReflectionConverter类中,canConvert方法中的type != eventHandlerType被删除了,使得原来的漏洞利用方式可以再次被利用。
由于在Xstream1.4.10中的com.thoughtworks.xstream.XStream类增加了setupDefaultSecurity()方法和InternalBlackList转换器,通过黑名单的形式对漏洞进行防御。但是安全模式默认不开启,必须在初始化后才可以使用,eg:XStream.setupDefaultSecurity(xStream)。导致防御失效,造成漏洞的第二次出现。
2.3.2 补丁分析
XStream1.4.11版本中,在com.thoughtworks.xstream.XStream更改安全模式初始化方法中的securityInitialized标志位。在调用InternalBlackList转换器中的canConvert方法时,可以进行黑名单匹配,从而防御了此漏洞。
2.3.3 漏洞防御
在Xstream1.4.11中的com.thoughtworks.xstream.XStream类中InternalBlackList类会对java.beans.EventHandler进行过滤,java.beans.EventHandler执行marshal或者unmarshal方法时,会抛出异常终止程序。
3 XStream 远程代码执行漏洞 3.1 漏洞信息
3.1.1 漏洞简介
● 漏洞名称:XStream Remote Code Execution Vulnerability
● 漏洞编号:CVE-2020-26217
● 漏洞类型:Remote Code Execution
● CVSS评分:CVSS v2.0:无, CVSS v3.0:8.0
● 漏洞危害等级:高危
3.1.2 漏洞概述
包含类型信息的流在unmarshalling时,会再次创建之前写入的对象。因此XStream会基于这些类型信息创建新的实例。攻击者可以操控XML数据,将恶意命令注入在在可以执行任意shell命令的对象中,实现漏洞的利用。
3.1.3 漏洞利用条件
无
3.1.4 漏洞影响
影响版本:XStream = 1.4.13
3.1.5 漏洞修复
获取XStream最新版本,下载链接:https://x-stream.github.io/download.html
3.2 漏洞复现
3.2.1 环境拓扑
3.2.2 应用协议
8080/HTTP
3.2.3 环境搭建
基于Windows平台,使用环境目录下的xstreamdemo环境,拷贝后使用Idea打开xstreamdemo文件夹,下载maven资源,运行DemoApplication类,即可启动环境。效果如图。
3.2.4 漏洞复现
运行sniper工具箱,填写表单信息,点击Attack,效果如图。
3.3 漏洞分析
3.3.1 代码分析
代码分析:传入的payload首先会在com.thoughtworks.xstream.XStream的fromXML()方法中处理,在进入unmarshal()方法中进行解集。
在com.thoughtworks.xstream.core.AbstractTreeMarshallingStrategy类中的unmarshal()方法中调用start()方法进行Java对象转换。
在com.thoughtworks.xstream.core.TreeUnmarshaller类中的start()方法通过调用readClassType()获取type类型。
在readClassType()方法中调用readClassAttribute方法。
进入readClassAttribute方法调用aliasForSystemAttribute方法获取别名。调用getAttribute方法,获取reader对象中记录的外部传入XML数据中是否存在对应的标签,如果不存在则返回null。
回到HierarchicalStreams#readClassType方法中调用realClass方法,通过别名在wrapped对象中的Mapper中循环查找,获取与别名对应的类。
在DefaultMapper中,通过反射,获取到string标签传入的class,并将类存入realClassCache对象中。
回到TreeUnmarshaller#start方法,调用convertAnother方法。进入convertAnother方法后,调用lookupConverterForType方法,寻找对应类型的转换器。进入lookupConverterForType方法,循环获取转换器列表中的转换器,调用转换器类中的canConvert方法判断选出的转换器是否可以对传入的type类型进行转换。
转换器ReflectionConverter中canConvert方法判断,传入的type非null,返回true,表示可以使用ReflectionConverter转换器进行转换。
回到DefaultConverterLookup#lookupConverterForType方法,将选取的converter与对应的type存入typeToConverterMap。
回到TreeUnmarshaller#convertAnother方法中,调用this.convert方法。
首先判断传入的xml数据中是否存在reference标签,如果不存在,则将当前标签压入parentStack栈中,并调用父类的convert方法。
在com.thoughtworks.xstream.converters.reflection.AbstractReflectionConverter.duUnmarshal()方法获取下面的节点元素iter java.util.ArrayList$Itr。
具体流程如下:调用getFieldOrNull方法,判断xml格式中传入的标签名在目标类中是否存在对应属性。
在调用reader.getNodeName()方法获取标签名,并赋值给originalNodeName。
调用realMember方法获取反序列化属性的名称。
调用readClassAttribute方法获取iter标签中传入的类名
调用realClass获取上述过程中类名对应的类,并调用unmarshallField方法进行解析。
进入方法中,寻找对应type的转换器,使用选中的ReflectionConverter转换器进行解组。
使用ReflectionConverter convert处理java.util.ArrayList$Itr ,在duUnmarshal()方法获取cursor标签和cursor标签下的参数。(调用unmarshallField方法,与上述流程相似)
调用this.reflectionProvider.writeField方法,将参数值传入对象中。
回到AbstractReflectionConverter#doUnmarshal方法中获取后续的标签及其参数(分别为lastRet,expectedModCount,outer-class)。
按照同样的反序列化流程获取属性值,并写入对象。
解析outer-class标签,由于type是java.util.ArrayList,选择转换器是CollectionConverter。
调用CollectionConverter#unmarshal方法进行反序列化。
调用CollectionConverter#populateCollection -> CollectionConverter#addCurrentElementToCollection->AbstractCollectionConverter#readItem方法。最终调用realClass方法获取type类,获取过程中将outer-class标签下的子标签存入realClassCache中。
回到AbstractCollectionConverter#readBareItem方法调用convertAnother方法,按照之前的流程进行反序列化,为属性赋值,并写入对象。
最终返回ProcessBuilder对象,写入FilterIterator对象中。
在按照获取java.util.ArrayList$Itr对象相同的流程获取javax.imageio.ImageIO$ContainsFilter对象,通过反序列化为其内部的method属性和name属性进行赋值。
在选择转换器的过程中,由于method属性的类型是java.lang.reflect.Method,因此选择对应的转换器为JavaMethodConverter。
调用JavaMethodConverter#unmarshal方法进行xml数据解析,获取java.lang.processBuilder类中的start方法对象,写入到javax.imageio.ImageIO$ContainsFilter对象中。
再按照相同的流程,将start方法名写入name属性中。
将FilterIterator对象返回给最初的iterator对象中。
调用iterator.next()方法时,会调用其实现类FilterIterator中的next方法。
进入调用advance方法,调用filter方法时,会通过反射执行ProcessBuilder对象中的start方法,从而造成代码执行。
3.3.2 补丁分析
XStream1.4.11版本中,在com.thoughtworks.xstream.XStream更改安全模式初始化方法中的securityInitialized标志位。在调用InternalBlackList转换器中的canConvert方法时,可以进行黑名单匹配,从而防御了此漏洞。
3.3.3 漏洞防御
XStream1.4.14版本中,在com.thoughtworks.xstream.XStream的黑名单添加java.lang.ProcessBuilder和javax.imageio.ImageIO$ContainsFilter。从而防御了此漏洞。
参考链接
https://blog.csdn.net/yaomingyang/article/details/80981004 https://github.com/x-stream/xstream/compare/XSTREAM_1_4_6...XSTREAM_1_4_7 https://github.com/x-stream/xstream/compare/XSTREAM_1_4_10...XSTREAM_1_4_11 https://github.com/x-stream/xstream/compare/XSTREAM_1_4_13...XSTREAM_1_4_14