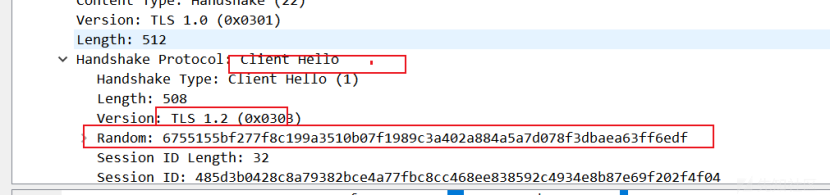
Apache Shiro身份验证绕过漏洞(CVE-2022-40664)
Apache Shiro身份验证绕过漏洞(CVE-2022-40664)
本文转自 安博通 并作补充
漏洞信息
CVE编号:CVE-2022-40664
CNVD编号:CNVD-2022-68497
Apache Shiro是一款功能强大且易于使用的Java安全框架,主要包含身份验证、授权、加密和会话管理等功能,可用于保护任何应用程序。
- 身份验证:用户登录
- 授权:访问控制
- 加密:保护或隐藏数据不被窥探
- 会话管理:管理每个用户的状态
Apache Shiro身份验证绕过漏洞,是通过RequestDispatcher转发或包含时Shiro中的身份验证绕过而产生的漏洞。在Apache Shiro 1.10.0之前,攻击者可构造恶意代码利用该漏洞绕过shiro的身份验证,从而获取用户的身份权限。
影响范围
Apache Shiro < 1.10.0
修复建议
直接升级,升级补丁链接如下:
安全防护
该漏洞是代码中函数逻辑问题导致的。当代码中存在一些特殊的调用和逻辑时,就可能触发该漏洞,因此远程请求是合法请求,没有恶意特征,安全厂商暂无法提取规则。
漏洞研究
漏洞复现
问题复现demo代码。
两个URL分别为/permit/{value}和/filterOncePerRequest/{value} 。
请求/permit/{value}时,被要求鉴权并拒绝。
请求/filterOncePerRequest/{value}时,成功绕过鉴权。



代码研究
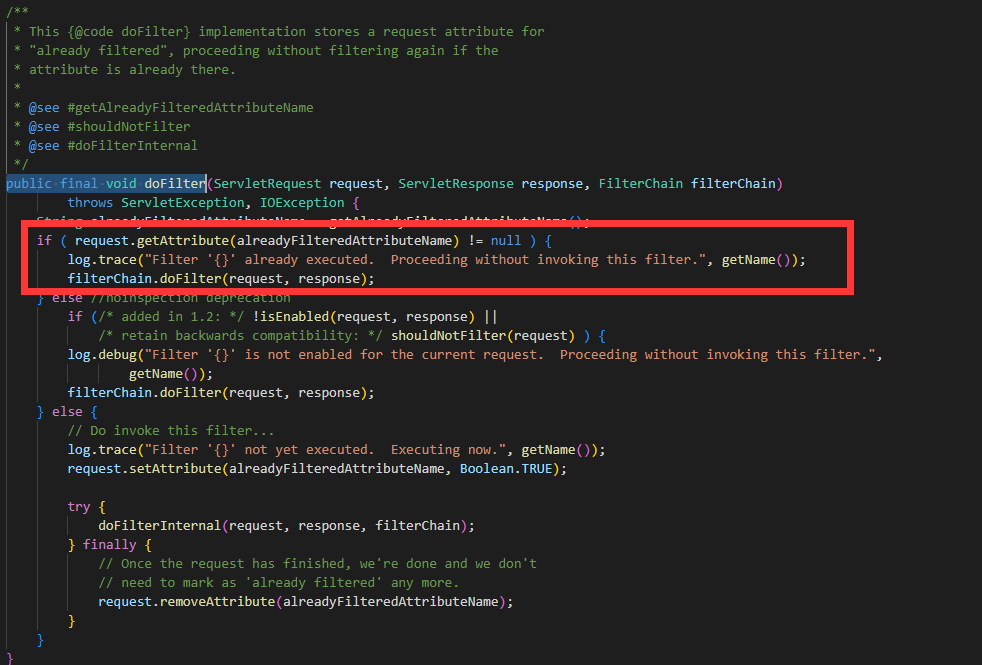
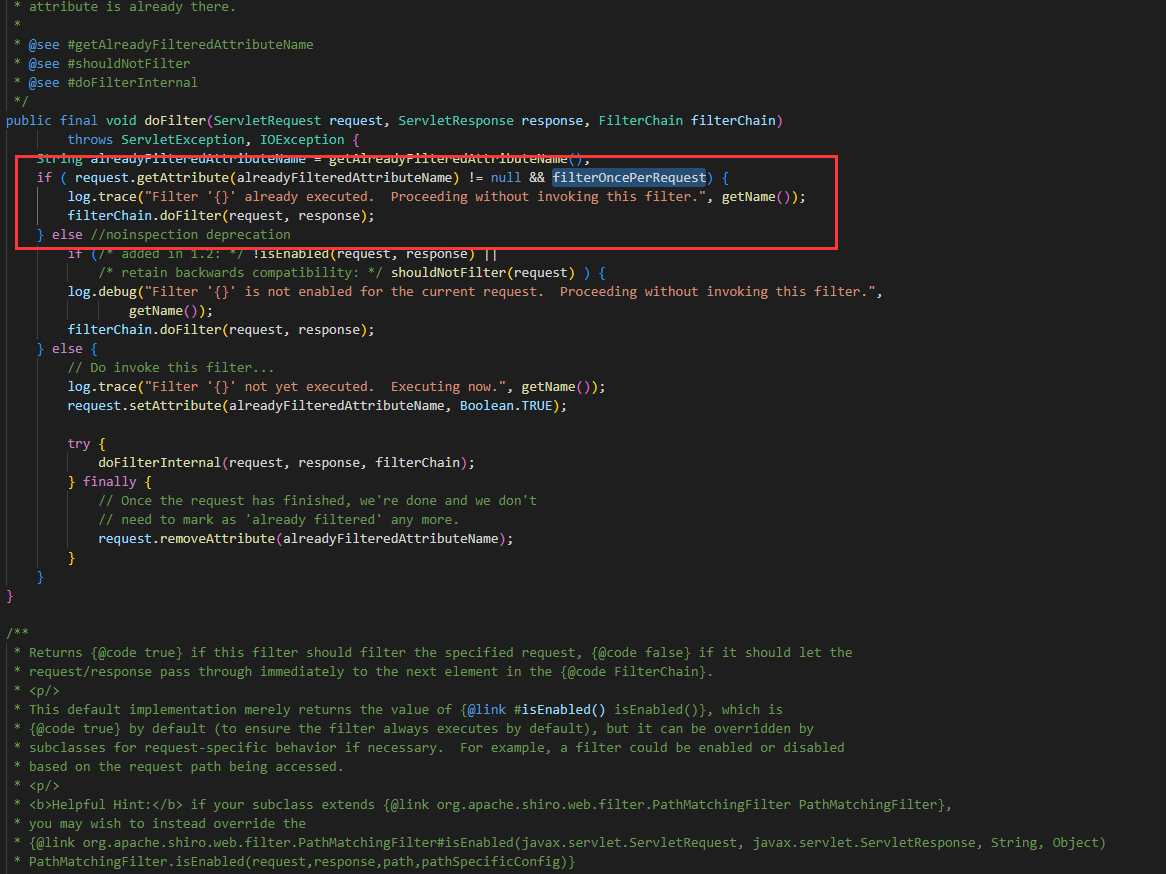
Shiro 1.9(漏洞版本)和1.10(修复后版本),修改点在org.apache.shiro.web.servlet.OncePerRequestFilter.doFilter处,修改前1.9版本如下:
修改后1.10版本如下:
显然在判断request.getAttribute(alreadyFilteredAttributeName) 不为空的同时,添加了必须保证filterOncePerRequest也为True的条件。
从上面代码可以看出,在该请求处理过第一次之后,为请求添加了属性shiroFilter.FILTERED=true,在第二次forward请求进来时,会进到第一个if,跳过本Filter的执行。这种处理方式可能就是漏洞产生的原因。
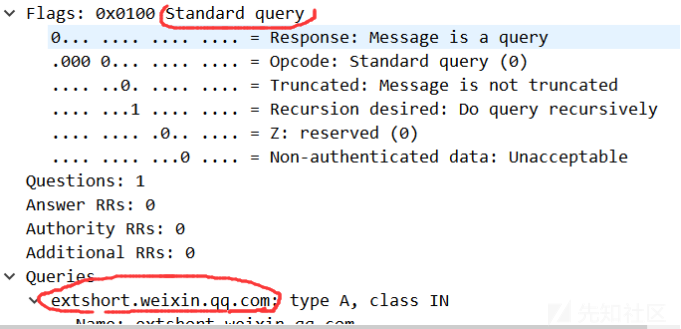
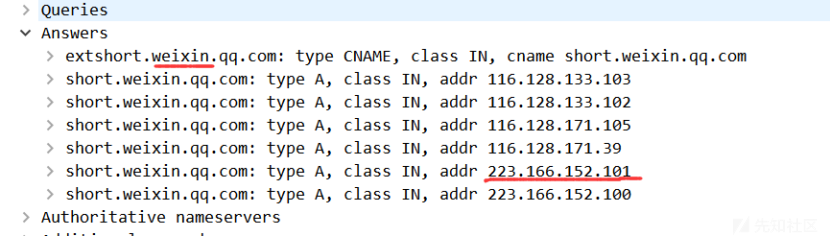
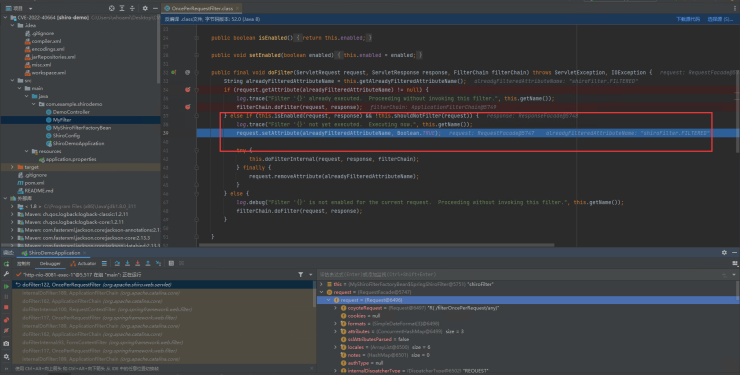
在改动处打断点并debug,发送如下请求:
2
3
4
5
6
7
8
Host: 172.31.1.101:8081
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:105.0) Gecko/20100101 Firefox/105.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8
Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2
Accept-Encoding: gzip, deflate
Connection: keep-alive
Upgrade-Insecure-Requests: 1经过判断,被判定为Filter ‘{}’ not yet executed. Executing now,表明该请求并没有进入过滤器。
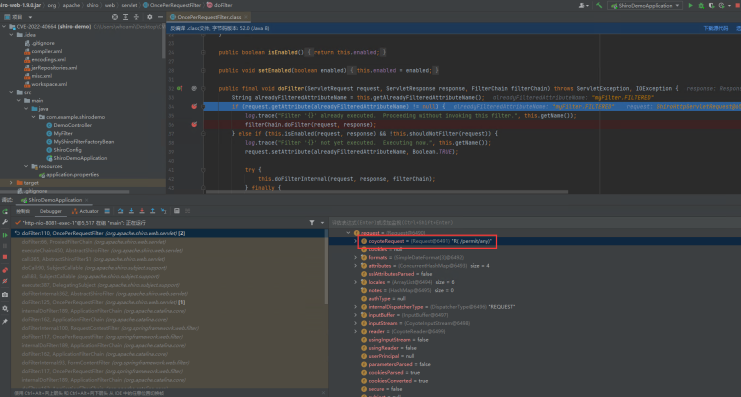
如代码所示,发送GET /filterOncePerRequest/any请求后,会使用内部forward命令,再次发起GET /permit/any请求。
这时发现对于forward请求拦截器根本不会拦截,由此可见漏洞原因确实如前文所述:在该请求处理第一次后,为请求添加了属性shiroFilter.FILTERED=true,在第二次forward请求进来时,会进到第一个if,跳过本Filter的执行,直接绕过了filter拦截器。
原因分析
因为代码逻辑存在漏洞,1.10.0之前的版本在请求forward时不进行拦截鉴权,导致在代码里存在对请求进行forward处理时,对应请求会绕过鉴权的问题。