Android逆向-获取APP签名
Android逆向-获取APP签名
本文转自Taardisaa 并作补充
很久以前开的blog,关于如何获取APP签名。不知道为啥要写这个了。
Android逆向-APP签名
生成JKS签名
Android studio 如何生成jks签名文件 - 简书 (jianshu.com)
打开AndroidStudio
然后
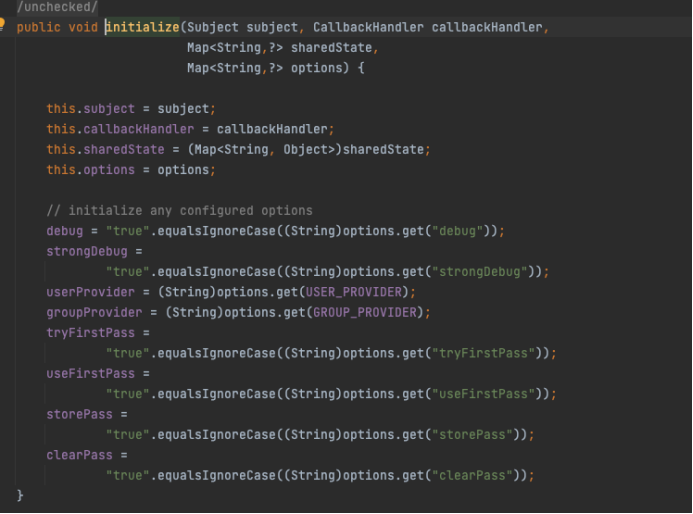
Key store path选择Create New然后设置好存储路径,密码也设置一下(偷懒写个123456)
Key的别名就叫key,密码一样简单。然后剩下的
Certificate全填taardis,Country Code填11451。反正创建成功后,就在选定路径下出现了
jks密钥文件。
APK签名
将APK魔改,重新打包后,需要重新签名。
参考:Android之通过 apksigner 对 apk 进行 手动签名_恋恋西风的博客-CSDN博客
成功后提示:
获取APK签名
首先APK解包:
然后在
META-INF文件夹拿到CERT.RSA文件。之后:
不过Keytool似乎是Java的工具,不管了现在用不上。
JEB/JADX
这种反编译器也能直接看到APK的签名信息。
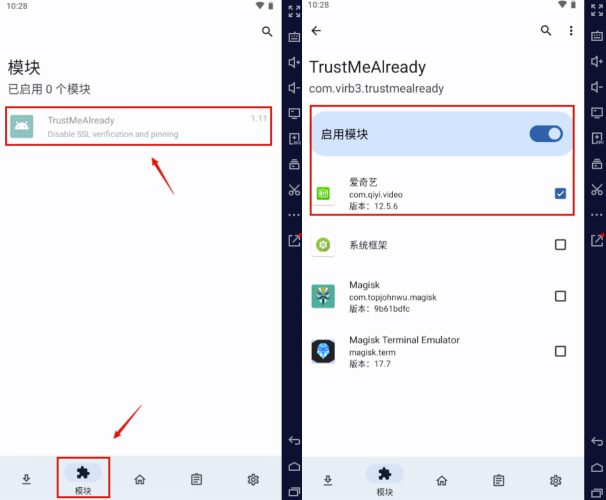
MT APP签名检查及绕过
L-JINBIN/ApkSignatureKillerEx: 新版MT去签及对抗 (github.com)
从“去除签名验证”说起 - 腾讯云开发者社区-腾讯云 (tencent.com)
过签名校验(2) – MT 的 IO 重定向实践 - 『移动安全区』 - 吾爱破解 - LCG - LSG |安卓破解|病毒分析|www.52pojie.cn
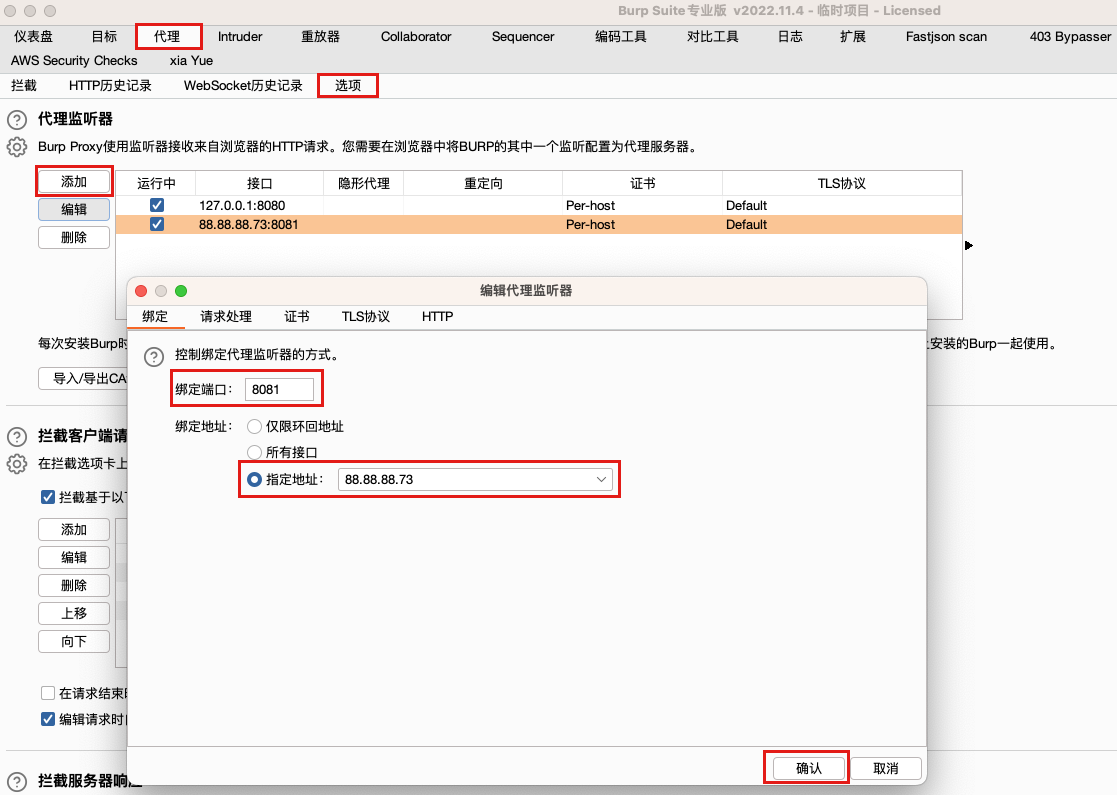
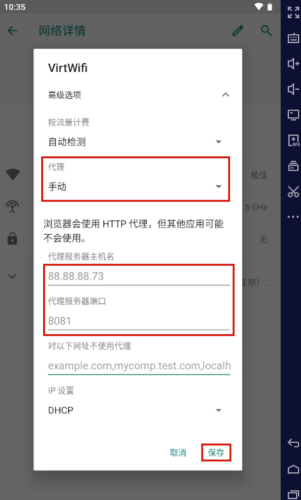
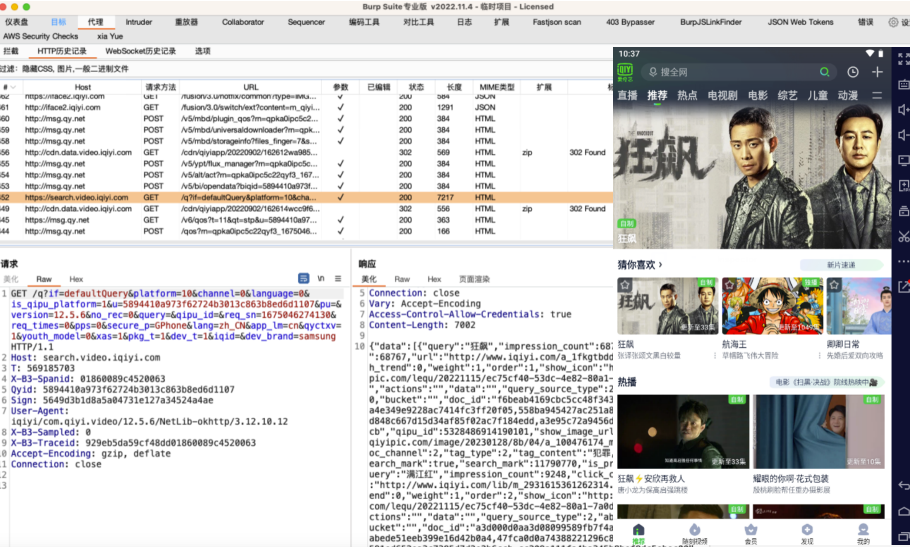
MT提供的签名绕过方式能够实现对API和APK方式的绕过。但是对于SVC的则无能为力。
2
3
4
String signatureFromAPI = md5(signatureFromAPI());
String signatureFromAPK = md5(signatureFromAPK());
String signatureFromSVC = md5(signatureFromSVC());
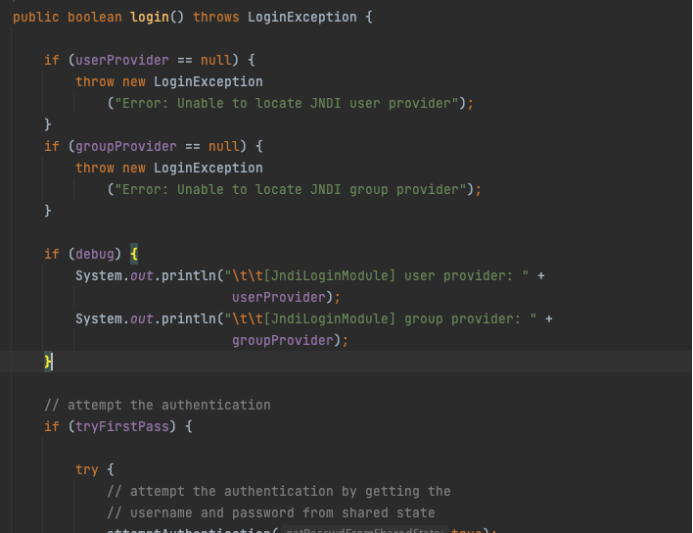
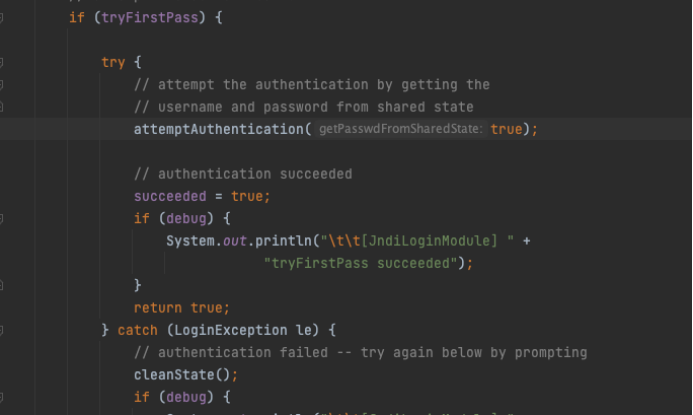
API检测
用
PackageManager直接获得签名。
2
3
4
5
6
7
8
9
try {
PackageInfo info = getPackageManager().getPackageInfo(getPackageName(), PackageManager.GET_SIGNATURES);
return info.signatures[0].toByteArray();
} catch (PackageManager.NameNotFoundException e) {
throw new RuntimeException(e);
}
}
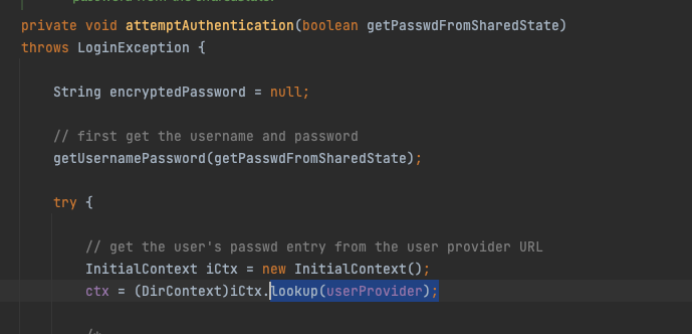
APK检测
找到APP私有文件夹下的
base.apk,然后得到签名
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
try (ZipFile zipFile = new ZipFile(getPackageResourcePath())) {
Enumeration<? extends ZipEntry> entries = zipFile.entries();
while (entries.hasMoreElements()) {
ZipEntry entry = entries.nextElement();
if (entry.getName().matches("(META-INF/.*)\\.(RSA|DSA|EC)")) {
InputStream is = zipFile.getInputStream(entry);
CertificateFactory certFactory = CertificateFactory.getInstance("X509");
X509Certificate x509Cert = (X509Certificate) certFactory.generateCertificate(is);
return x509Cert.getEncoded();
}
}
} catch (Exception e) {
e.printStackTrace();
}
return null;
}
SVC检测
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
try (ParcelFileDescriptor fd = ParcelFileDescriptor.adoptFd(openAt(getPackageResourcePath()));
ZipInputStream zis = new ZipInputStream(new FileInputStream(fd.getFileDescriptor()))) {
ZipEntry entry;
while ((entry = zis.getNextEntry()) != null) {
if (entry.getName().matches("(META-INF/.*)\\.(RSA|DSA|EC)")) {
CertificateFactory certFactory = CertificateFactory.getInstance("X509");
X509Certificate x509Cert = (X509Certificate) certFactory.generateCertificate(zis);
return x509Cert.getEncoded();
}
}
} catch (Exception e) {
e.printStackTrace();
}
return null;
}
绕过
Java层的东西不多
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
try {
// Native层Hook
System.loadLibrary("SignatureKiller");
} catch (Throwable e) {
System.err.println("Load SignatureKiller library failed");
return;
}
// 读取/proc/self/maps读取APP路径
String apkPath = getApkPath(packageName);
if (apkPath == null) {
System.err.println("Get apk path failed");
return;
}
// 读取自身APK文件(私有目录下的base.apk)
File apkFile = new File(apkPath);
// 在APP私有目录下创建origin.apk文件
File repFile = new File(getDataFile(packageName), "origin.apk");
try (ZipFile zipFile = new ZipFile(apkFile)) {
// 将APK中的origin.apk给提取出来(origin.apk是MT去签是生成的,是初始没有被去签的APK)
String name = "assets/SignatureKiller/origin.apk";
ZipEntry entry = zipFile.getEntry(name);
if (entry == null) {
System.err.println("Entry not found: " + name);
return;
}
// 读取出来
if (!repFile.exists() || repFile.length() != entry.getSize()) {
try (InputStream is = zipFile.getInputStream(entry); OutputStream os = new FileOutputStream(repFile)) {
byte[] buf = new byte[102400];
int len;
while ((len = is.read(buf)) != -1) {
os.write(buf, 0, len);
}
}
}
} catch (IOException e) {
throw new RuntimeException(e);
}
// 传入底层so Hook
hookApkPath(apkFile.getAbsolutePath(), repFile.getAbsolutePath());
}然后看Native层,实际上是XHook,用于替换libc函数。
实际上就做了个字符串替换,有意将原本要打开的APK替换成
origin.apk。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
const char *repPath__;
int (*old_open)(const char *, int, mode_t);
static int openImpl(const char *pathname, int flags, mode_t mode) {
//XH_LOG_ERROR("open: %s", pathname);
if (strcmp(pathname, apkPath__) == 0){
//XH_LOG_ERROR("replace -> %s", repPath__);
return old_open(repPath__, flags, mode);
}
return old_open(pathname, flags, mode);
}
JNIEXPORT void JNICALL
Java_bin_mt_signature_KillerApplication_hookApkPath(JNIEnv *env, __attribute__((unused)) jclass clazz, jstring apkPath, jstring repPath) {
apkPath__ = (*env)->GetStringUTFChars(env, apkPath, 0);
repPath__ = (*env)->GetStringUTFChars(env, repPath, 0);
xhook_register(".*\\.so$", "openat64", openat64Impl, (void **) &old_openat64);
xhook_register(".*\\.so$", "openat", openatImpl, (void **) &old_openat);
xhook_register(".*\\.so$", "open64", open64Impl, (void **) &old_open64);
xhook_register(".*\\.so$", "open", openImpl, (void **) &old_open);
xhook_refresh(0);
}通过Hook open函数,可以把基于APK读取的签名方式给绕过。
下面提供一个绕过基于PackageManager的:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
// 构造一个假的签名
Signature fakeSignature = new Signature(Base64.decode(signatureData, Base64.DEFAULT));
Parcelable.Creator<PackageInfo> originalCreator = PackageInfo.CREATOR;
Parcelable.Creator<PackageInfo> creator = new Parcelable.Creator<PackageInfo>() {
public PackageInfo createFromParcel(Parcel source) {
PackageInfo packageInfo = originalCreator.createFromParcel(source);
if (packageInfo.packageName.equals(packageName)) { //
if (packageInfo.signatures != null && packageInfo.signatures.length > 0) {
packageInfo.signatures[0] = fakeSignature; // 将虚假的签名放入packageInfo,取代原来的
}
if (Build.VERSION.SDK_INT >= Build.VERSION_CODES.P) {
if (packageInfo.signingInfo != null) {
Signature[] signaturesArray = packageInfo.signingInfo.getApkContentsSigners();
if (signaturesArray != null && signaturesArray.length > 0) {
signaturesArray[0] = fakeSignature;
}
}
}
}
return packageInfo;
}
public PackageInfo[] newArray(int size) {
return originalCreator.newArray(size);
}
};
try {
// 用假的creator替换原来的PackageInfo.CREATOR
findField(PackageInfo.class, "CREATOR").set(null, creator);
} catch (Exception e) {
throw new RuntimeException(e);
}
if (Build.VERSION.SDK_INT >= Build.VERSION_CODES.P) {
// 解除某些Android系统API的使用限制?
HiddenApiBypass.addHiddenApiExemptions("Landroid/os/Parcel;", "Landroid/content/pm", "Landroid/app");
}
try {
// 清空签名缓存
Object cache = findField(PackageManager.class, "sPackageInfoCache").get(null);
// noinspection ConstantConditions
cache.getClass().getMethod("clear").invoke(cache);
} catch (Throwable ignored) {
}
try {
// 清空签名缓存
Map<?, ?> mCreators = (Map<?, ?>) findField(Parcel.class, "mCreators").get(null);
// noinspection ConstantConditions
mCreators.clear();
} catch (Throwable ignored) {
}
try {
// 清空签名缓存
Map<?, ?> sPairedCreators = (Map<?, ?>) findField(Parcel.class, "sPairedCreators").get(null);
// noinspection ConstantConditions
sPairedCreators.clear();
} catch (Throwable ignored) {
}
}
参考
Java Keytool 介绍 - 且行且码 - 博客园 (cnblogs.com)
获取Android应用签名的几种方式 - 简书 (jianshu.com)
Android studio 如何生成jks签名文件 - 简书 (jianshu.com)
apktool重新打包时报错_apktool 忽略错误信息__y4nnl2的博客-CSDN博客